Chapter 19 Immune estimation
In this section, we will look at Deconvolution methods (CIBERSORT, TIMER etc) for estimating immune fractions and cell types
Deconvolution was performed using the TIMER website, which lists results from TIMER, XCELL, CIBERSORT, EPIC, MMPCOUNTER
TPM counts were used for this analysis (using Rat gene names) on the TIMER website ()
ProgSpecCD45=read.csv("../data/RNA_expression/CD45_TPM_rgd_names_prog_12-08_estimation_matrix.csv")
colnames(ProgSpecCD45)=gsub("X", "", colnames(ProgSpecCD45))
CharSpecCD45=read.csv("../data/RNA_expression/CD45-tpm-rgdnames-char-2020-11-22-estimation_matrix.csv")
colnames(CharSpecCD45)=gsub("X", "", colnames(CharSpecCD45))
## merge the two together
output1=merge(ProgSpecCD45, CharSpecCD45, by.x="cell_type", by.y="cell_type", all=T)19.1 Overview of the cell types
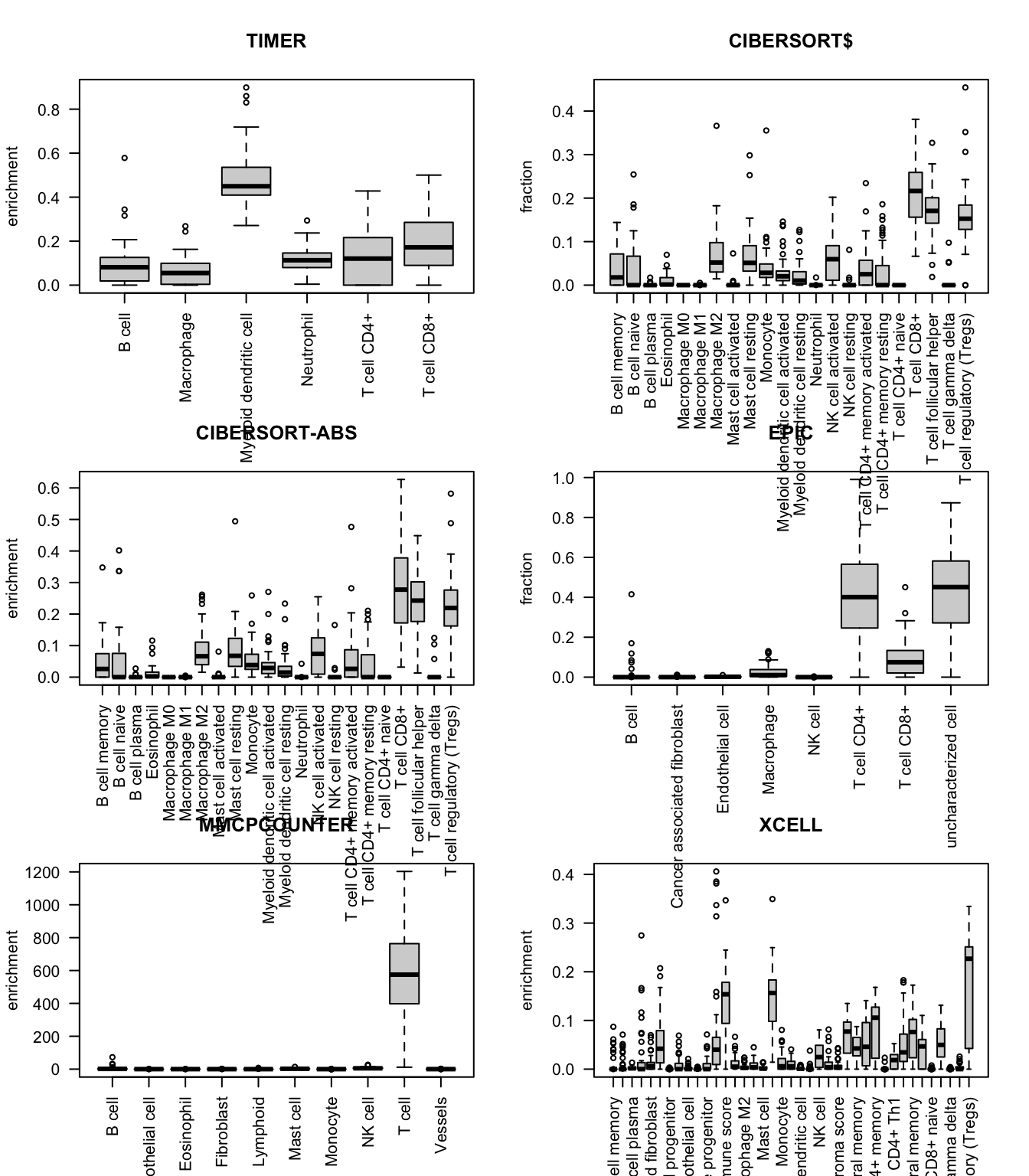
Below, we will look at the enrichment scores of specific cell types compared to others using these different methods. It appears that most methods have scores which skews towards high representation of T cells:
TIMER for example shows an enrichment of dendritic and CD8 T cells. EPIC in contrast shows enrichment for CD4+ and to a lesser extend CD8 T cells MMPCOUNTER puts an unusually large weighting to T cells and this does not fit our FACS analysis XCELL enriches for T cells
RowNames=c("TIMER", "CIBERSORT$", "CIBERSORT-ABS", "EPIC", "MMCPCOUNTER", "XCELL")
Type=c("enrichment", "fraction", "enrichment", "fraction", "enrichment", "enrichment")
par(mfrow=c(3, 2))
for (i in 1:length(RowNames)){
timSamples=output1[grep(RowNames[i], output1$cell_type), ]
rownames(timSamples)=sapply(strsplit(as.character(timSamples$cell_type), "_"), function(x) x[1])
boxplot(t(timSamples[ ,-1]), las=2, main=RowNames[i], ylab=Type[i])
}
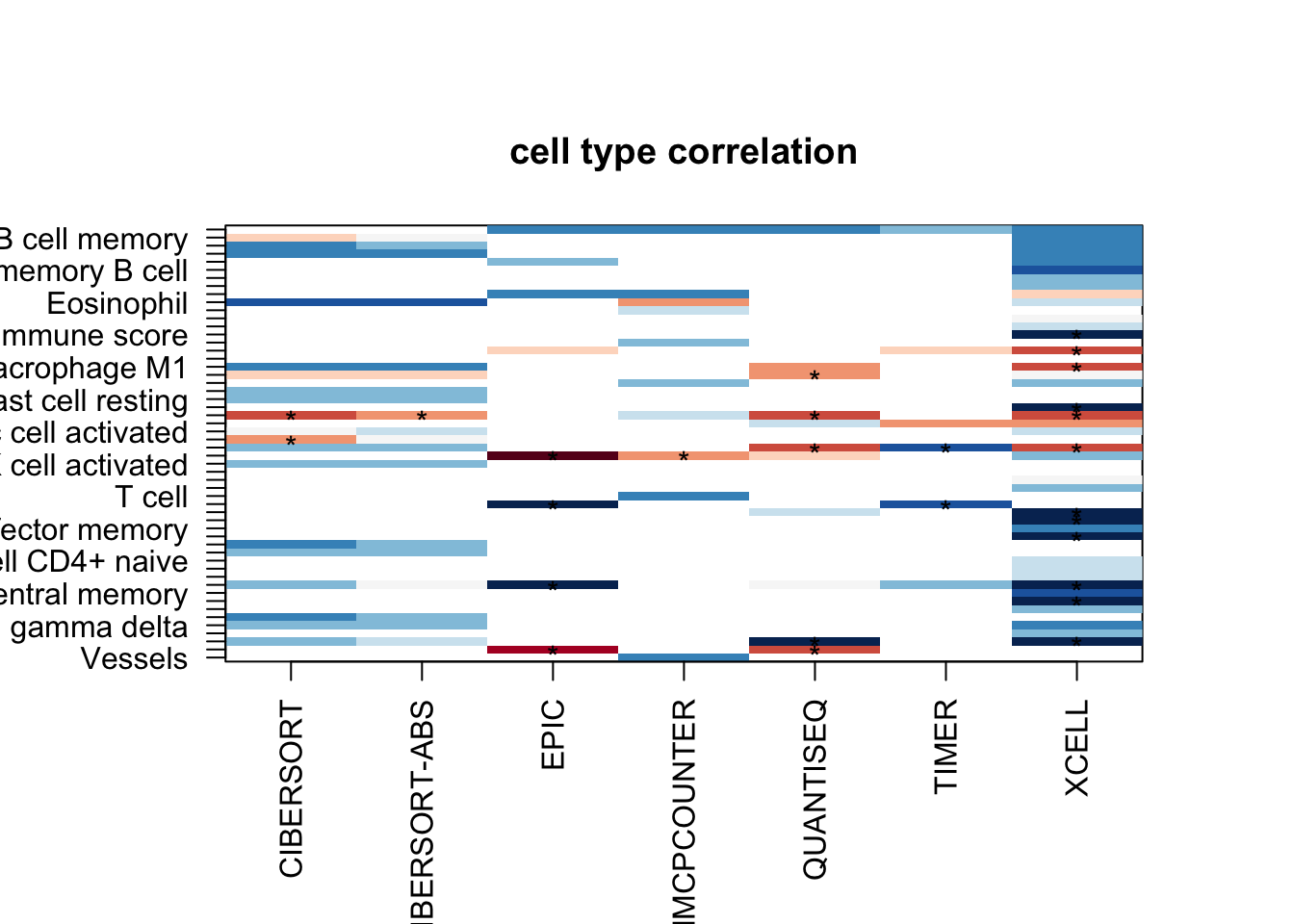
19.2 characterisation cohort: assoc with size
Associations with size? Perform a correlation test between all of the information above and tumor size.
We obtain a matrix which is colored with a coefficient correlation (red is associative, blue is negatively associated). Correlations which are significant are marked with an asterisk:
sizeInfo=infoTableFinal$TumSize[match(colnames(CharSpecCD45)[-1], rownames(infoTableFinal))]
CorVals=rep(NA, nrow(CharSpecCD45))
names(CorVals)=CharSpecCD45$cell_type
CorValsP=CorVals
CorVals=sapply(1:nrow(CharSpecCD45), function(x) cor(t(CharSpecCD45[x, -1]), sizeInfo, use="complete"))
CorValsP=sapply(1:nrow(CharSpecCD45), function(x) cor.test(t(CharSpecCD45[x, -1]), sizeInfo, use="complete")$p.value)
naidx=which(CorValsP<0.05)
RNames1=sapply(strsplit(CharSpecCD45$cell_type, "_"), function(x) x[1])
RNamesMethod=sapply(strsplit(CharSpecCD45$cell_type, "_"), function(x) x[2])
df2=data.frame(cell=RNames1, method=RNamesMethod, cor=CorVals, p=CorValsP)
ax1=acast(df2[ ,c(1:3)], RNames1~RNamesMethod)
#df2=data.frame(cell=RNames1, method=RNamesMethod, cor=CorValsP)
ax2=acast(df2[ ,c(1:2, 4)], RNames1~RNamesMethod)
ax2[which(ax2>0.1, arr.ind=T)]=0
ax2[which(is.na(ax2), arr.ind = T)]=0
#par(oma=c(3, 5, 2, 2))
#OutputplotFun(ax1, scaleR="none", main="cell type correlation", classN="no", sigMat=ax2)
## Also plot these all separately
sizeInfoCut=infoTableFinal$SizeCat[match(colnames(CharSpecCD45)[-1], rownames(infoTableFinal))]
ttestVal=sapply(1:nrow(CharSpecCD45), function(x) wilcox.test(t(CharSpecCD45[x, -1])~sizeInfoCut)$p.value)
df3=data.frame(cell=RNames1, method=RNamesMethod, cor=ttestVal)
ax3=acast(df3, RNames1~RNamesMethod)
ax3[which(ax3>0.1, arr.ind=T)]=0
ax3[which(is.na(ax3), arr.ind = T)]=0
ttestP=sapply(1:nrow(CharSpecCD45), function(x) wilcox.test(t(CharSpecCD45[x, -1])~sizeInfoCut)$p.value)
ttestVal=sapply(1:nrow(CharSpecCD45), function(x) diff(t.test(t(CharSpecCD45[x, -1])~sizeInfoCut)$est))
df3=data.frame(cell=RNames1, method=RNamesMethod, val=ttestVal, p=ttestP)
ax3=acast(df3[ ,c(1:2, 4)], RNames1~RNamesMethod)
ax3[which(ax3>0.05, arr.ind=T)]=0
ax3[which(is.na(ax3), arr.ind = T)]=0
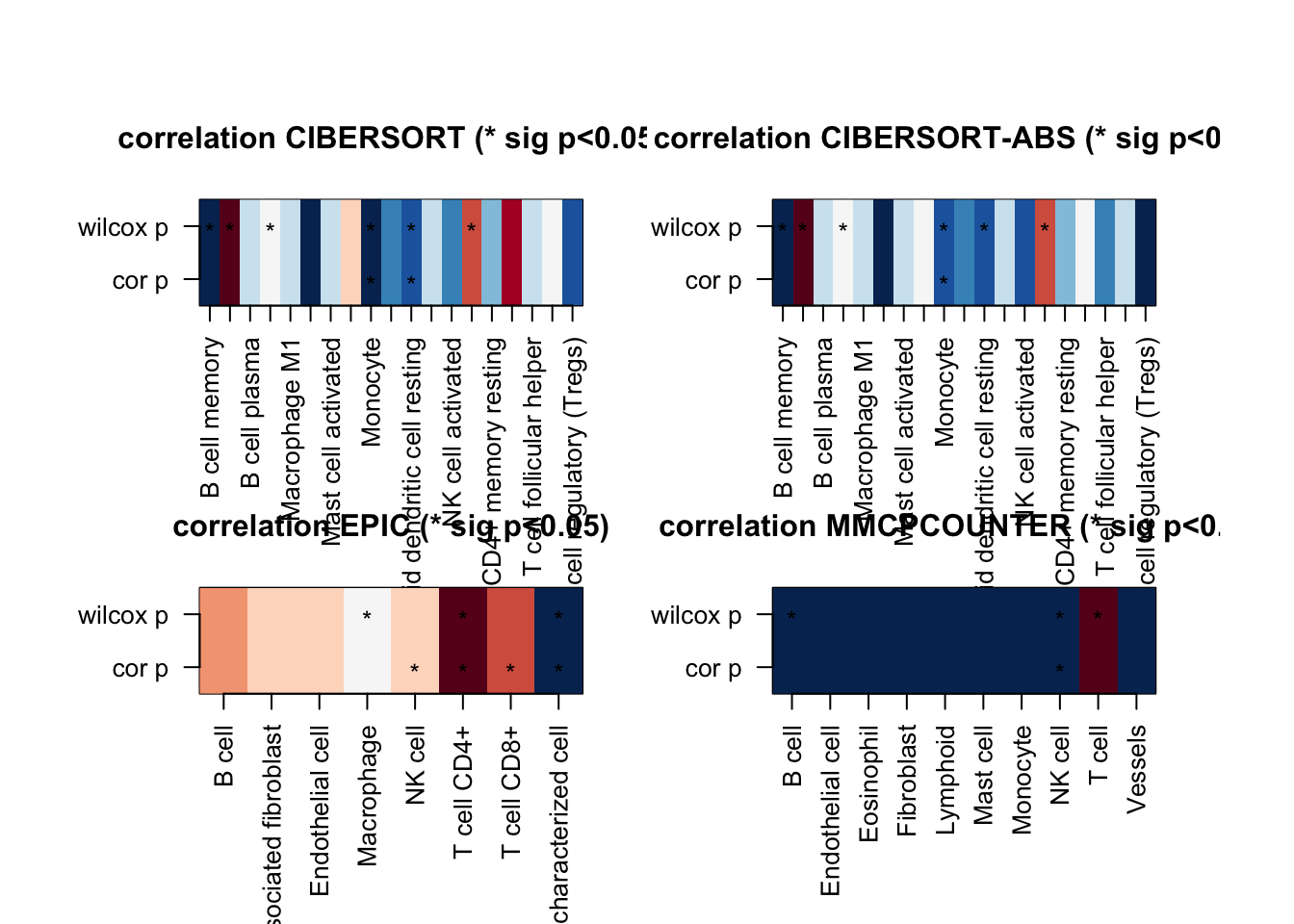
ax4=acast(df3[ ,c(1:3)], RNames1~RNamesMethod)The above matrices are sparse, and we can zoom in on specific methods to see whether there is an association
#pdf("~/Desktop/2F_characterisation_association_size_immune_types.pdf", width=8, height=5)
par(mfrow=c(2,2))
for (i in 1:ncol(ax1)){
t1=ax1[, i]
t2=which(!is.na(t1))
image(cbind(ax4[t2, i],ax4[t2, i]), col=RdBu[11:1], xaxt="none", yaxt="none",
main=sprintf("correlation %s (* sig p<0.1)", colnames(ax1)[i]))
axis(1, at=seq(0, 1, length=length(t2)), names(t1)[t2], las=2, cex=0.7)
axis(2, at=c(0,1),c("cor p", "wilcox p"), las=2, cex=0.7)
mx=which(ax2[ t2,i]>0)
text((mx-1)/(length(t2)-1), 0 , "*")
mx=which(ax3[ t2,i]>0)
text((mx-1)/(length(t2)-1), 1 , "*")
}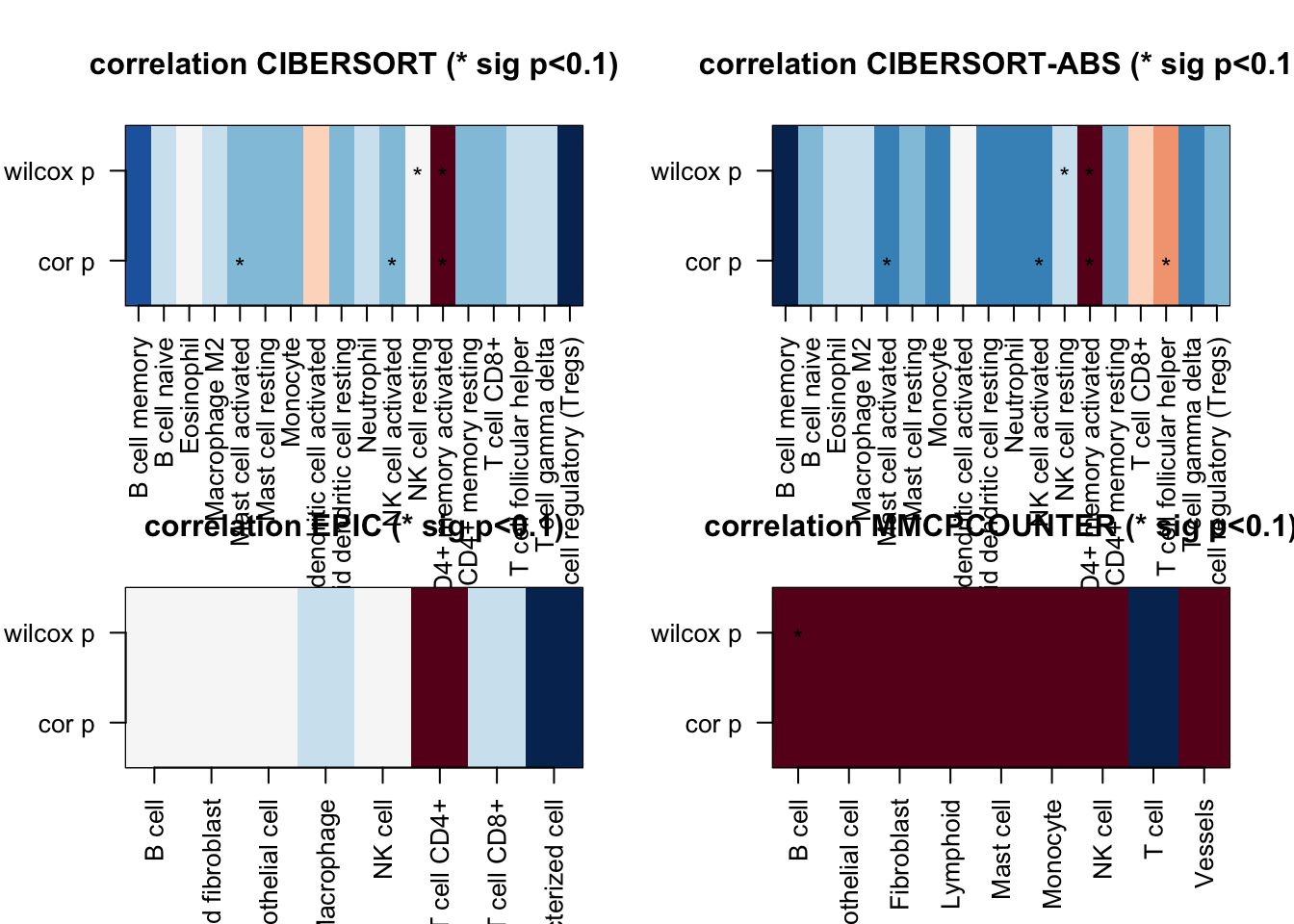
Figure 19.1: correlation coefficient values
#dev.off()
#write.csv(df2, file="nature-tables/2f_correlation_coefficients_pvalues.csv")
#write.csv(ax1, file="nature-tables/2f_correlation_coefficients.csv")
DT::datatable(df3, rownames=F, class='cell-border stripe',
extensions="Buttons", options=list(dom="Bfrtip", buttons=c('csv', 'excel')))Figure 19.2: correlation coefficient values
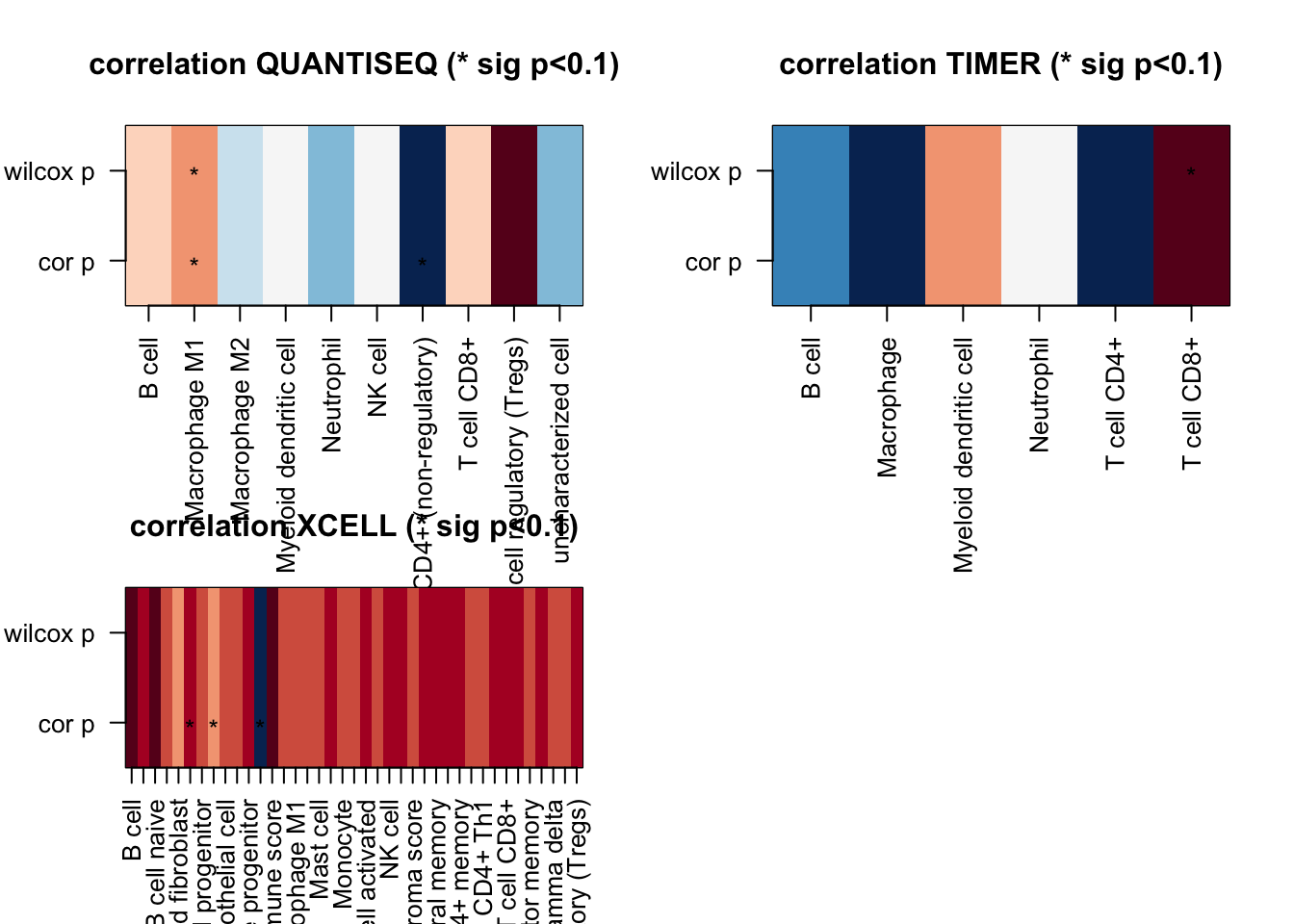
Figure 19.3: correlation coefficient values
These accompany the following plots with individual samples:
#pdf("~/Desktop/2F-sample-celltypes.pdf", height=6, width=7)
x2=c(colnames(CharSpecCD45)[order(sizeInfo)+1])
ax1=grep("TIMER", CharSpecCD45$cell_type)
T1melt=melt(CharSpecCD45[ax1, ])
T1melt$variable=factor(T1melt$variable, x2)
T1melt$NewID=infoTableFinal$TumorIDnew[match(T1melt$variable, rownames(infoTableFinal))]
ggplot(T1melt, aes(x=NewID, y=value, fill=cell_type))+geom_bar(stat="identity")+
ggtitle("TIMER:char cohort separately")+theme(axis.text.x = element_text(angle = 90))+
scale_fill_manual(values=c("#66C2A5", "#FED976", "#FEEBE2" ,"#AE017E", "#2171B5", "#BDD7E7", "#EFF3FF"))+theme_bw()+theme(axis.text.x = element_text(angle = 90))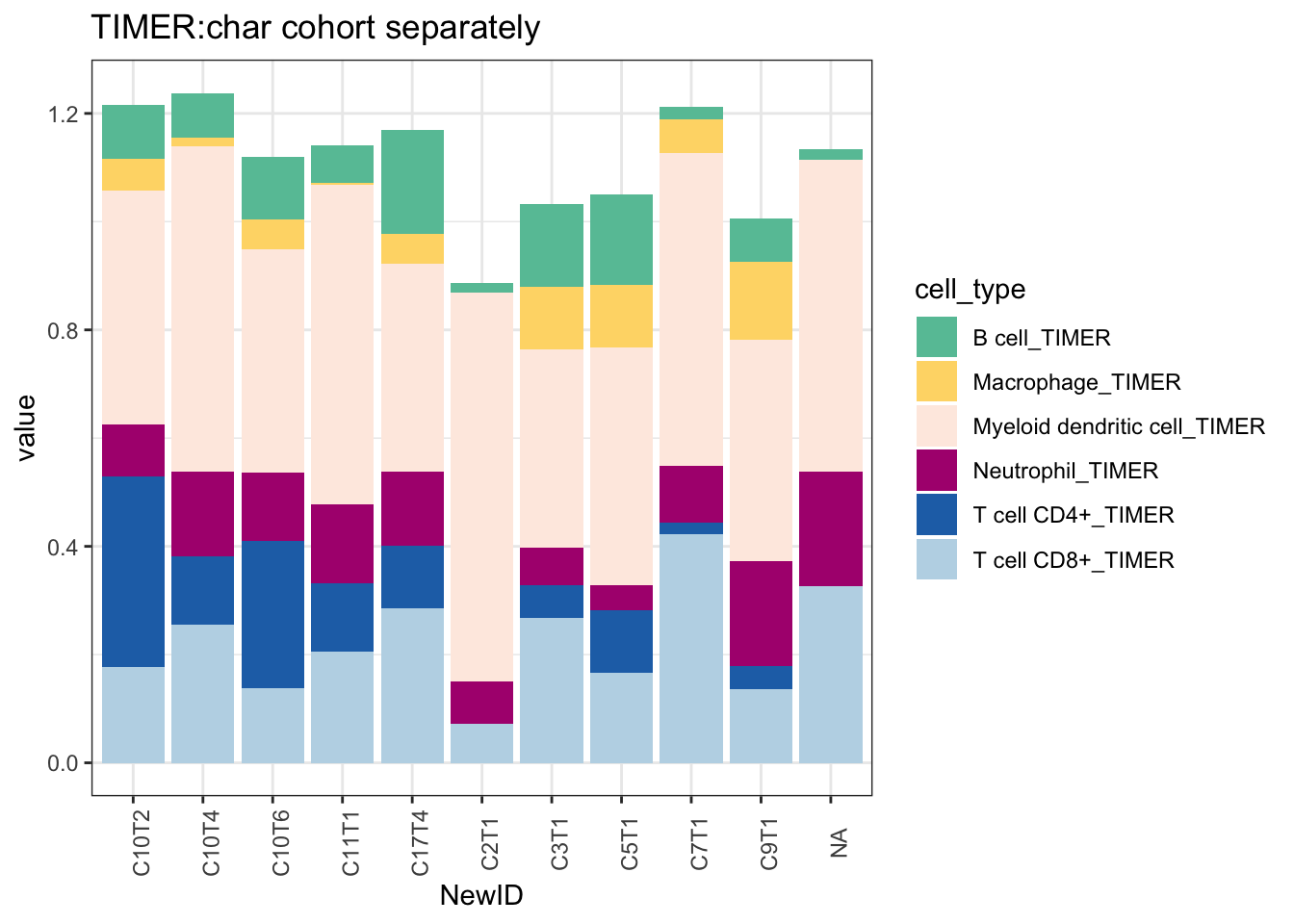
Figure 19.4: TIMER
And below is the result for CIBERSORT
ax1=grep("CIBERSORT$", CharSpecCD45$cell_type)
T1melt=melt(CharSpecCD45[ax1, ])
T1melt$variable=factor(T1melt$variable, x2)
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type))+geom_bar(stat="identity")+
ggtitle("CIBSERT:char cohort separately")+theme(axis.text.x = element_text(angle = 90))+theme_bw()+
theme(axis.text.x = element_text(angle = 90))
# Also do a version where the Bcells, Macrophages,NK, Mast Cells, CD4, CD8 Cells are merged together, NK
T1melt$cell_type2=substr(T1melt$cell_type, 1, 4)
T1melt$cell_type2[grep("CD8", T1melt$cell_type)]="T CD8"
T1melt$cell_type2[grep("CD4", T1melt$cell_type)]="T CD4"
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type2))+geom_bar(stat="identity")+
ggtitle("CIBSERT:char cohort separately")+theme(axis.text.x = element_text(angle = 90))+
scale_fill_manual(values=c("#66C2A5", "#E6F598", "#FED976", "#FC4E2A", "#bdbdbd", "#FEEBE2" ,"#AE017E", "#5E4FA2", "#2171B5", "#BDD7E7", "#EFF3FF"))+theme_bw()+theme(axis.text.x = element_text(angle = 90))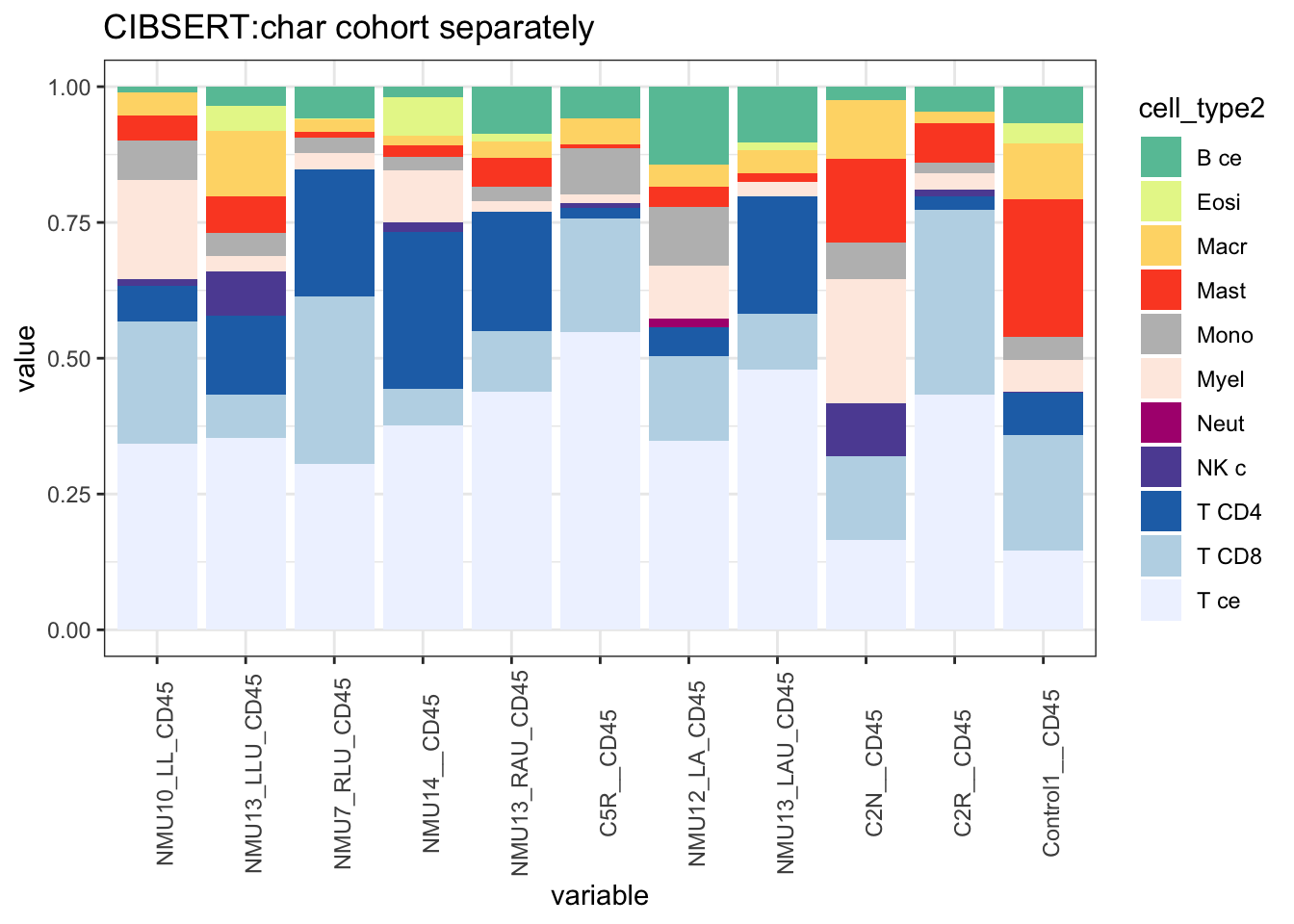
T1melt$sdat=paste(T1melt$variable, T1melt$cell_type2, sep=".")
T2=by(T1melt$value, T1melt$sdat, sum)
T2m=stack(T2)
T2m$ind1=sapply(strsplit(as.character(T2m$ind), "\\."), function(x) x[1])
T2m$ind2=sapply(strsplit(as.character(T2m$ind), "\\."), function(x) x[2])
T2mTab=acast(T2m[ ,c(1, 3:4)], ind2~ind1, value.var="values")
CorV=sapply(1:nrow(T2mTab), function(x) cor(T2mTab[x, ], sizeInfo, use="complete"))
CorVP=sapply(1:nrow(T2mTab), function(x) cor.test(T2mTab[x, ], sizeInfo, use="complete")$p.value)
wilP=sapply(1:nrow(T2mTab), function(x) wilcox.test(T2mTab[x, ]~ sizeInfoCut)$p.value)
# dev.off()
write.csv(T1melt, file="nature-tables/2f.csv")
19.3 Comparison with FACS data
In this section, we compare how well the estimates from RNAseq deconvolution methods associate with FACS data. Below is a heatmap showing the correlation coefficient of each cell type (by FACS) and the method,
Note that there are twice as manay samples with reliable myeloid derived cell information than for leukocytes.
## annotate the FACS data here
infoTableFinal$Name2=NA
infoTableFinal$Name2[which(infoTableFinal$Fraction=="CD45")]=paste(infoTableFinal$Rat_ID[which(infoTableFinal$Fraction=="CD45")], infoTableFinal$Location[which(infoTableFinal$Fraction=="CD45")], sep="")
m2=match(colnames(Fdata), infoTableFinal$Name2)
## get rid of the NA samples
naom=infoTableFinal$SampleID[m2[which(!is.na(m2))]]
mid=colnames(Fdata)[which(!is.na(m2))]
lx1=Fdata[, c(1, match(mid, colnames(Fdata)))]
out2=output1[, c(1,match(naom, colnames(output1)))]
#head(out2)
colnames(lx1)=colnames(out2)
# Run all the association tests here
## New Table
# -cd8
# Th
# Tregs
# B cells
# Macrophage
#
MergedTable=matrix(NA, ncol=21, nrow=1)
colnames(MergedTable)=colnames(out2)
tx1=sapply(strsplit(as.character(out2$cell_type), "_"), function(x) x[1])
MethodSumm=sapply(strsplit(as.character(out2$cell_type), "_"), function(x) x[2])
tabtx1=table(tx1)
TheseFracs=names(tabtx1)[which(tabtx1>3)]
testSetB=c("B cell", "MHCII-hi", "MHCII-lo", "Monocyte", "Neutrophil", "NK cells", "CD8", "Treg")
# "CD8", "Th", "Treg", "B cells", "NK cells", "DC", "Neutrophil", "Monocyte", "gd T", "MHCII-hi", "MHCII-lo")
testSet=TheseFracs[-2]#c("CD8", "CD4", "Treg", "B cell", "NK", "dendritic", "Neutrophil", "Monocyte", "gamma delta", "M1", "M2")
CMat=matrix(NA, nrow=length(testSet), ncol=length(unique(MethodSumm)))
rownames(CMat)=testSet
colnames(CMat)=unique(MethodSumm)
PMat=CMat
#testSet="M2"
#testSetB="MHCII-lo"
for (j in 1:length(testSet)){
CD8Table=rbind(lx1[grep(testSetB[j], lx1$cell_type), ],
out2[which(tx1==testSet[j]), ])
CD8Table[1,1]=paste(testSetB[j], "facs", sep="_")
ms=MethodSumm[which(tx1==testSet[j])]
par(mfrow=c(3,3))
cVals=sapply(2:nrow(CD8Table), function(x) cor(t(CD8Table[1, -1]), t(CD8Table[x, -1]), use="complete"))
cVals2=sapply(2:nrow(CD8Table), function(x) cor.test(t(CD8Table[1, -1]), t(CD8Table[x, -1]), use="complete")$p.value)
CMat[j, match(ms, colnames(CMat))]=cVals
PMat[j, match(ms, colnames(PMat))]=cVals2
MergedTable=rbind(MergedTable, CD8Table)
#for (i in 2:nrow(CD8Table)){
#a1=cor(t(CD8Table[1, -1]), t(CD8Table[i, -1]), use="complete")
#plot(t(CD8Table[1, -1]), t(CD8Table[i, -1]), main=CD8Table[i,1], ylab="method", xlab="FACS")
#text(min(t(CD8Table[1, -1]), na.rm=T)*2, max(t(CD8Table[i, -1]), na.rm=T), paste("r=", round(a1, digits=2), sep=""))
}
##for the following, find the terms and calculate the sum
testSetB=c("Macro", "Th", "B cell")
testSet=c("Macro", "CD4", "B cell")
rmThese=c("M0", "naive", NULL)
savTemp=matrix(NA, nrow=3, ncol=ncol(CMat))
rownames(savTemp)=paste("all", testSet, sep="")
savTempP=savTemp
for (j in 1:length(testSetB)){
CD8Table=lx1[grep(testSetB[j], lx1$cell_type), ]
CD8Table=colSums(CD8Table[, -1])
#rownames(CD8Table)="facs"
outB=out2[grep(testSet[j], out2$cell_type), ]
rm2=grep(rmThese[j], outB$cell_type)
if (length(na.omit(rm2))>0){
outB=outB[-rm2, ]
}
namOut=sapply(strsplit(as.character(outB$cell_type), "_"), function(x) x[2])
nam2=unique(namOut[which(duplicated(namOut))])
outC=sapply(nam2, function(x) colSums(outB[which(namOut==x), -1 ]))
outB=outB[-which(namOut%in%nam2), ]
rownames(outB)=sapply(strsplit(as.character(outB$cell_type), "_"), function(x) x[2])
allD=rbind(CD8Table, outB[, -1], t(outC))
rownames(allD)[1]="facs"
allD$method=rownames(allD)
# allD=data.matrix(allD)
#pdf(sprintf("rslt/Immune decomposition/correlations_combined_%s.pdf", testSetB[j]), width=10, height=10)
#ggplot(temp8, aes(x=method, y=value, col=variable))+geom_bar(stat="identity")+facet_wrap(~variable, scale="free_y")+theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))
par(mfrow=c(3,3))
for (i in 2:nrow(allD)){
a1=cor(t(allD[1, -ncol(allD)]), t(allD[i, -ncol(allD)]), use="complete")
a2=cor.test(t(allD[1, -ncol(allD)]), t(allD[i, -ncol(allD)]), use="complete")$p.value
savTemp[j, match(rownames(allD)[i], colnames(CMat))]=a1
savTempP[j, match(rownames(allD)[i], colnames(CMat))]=a2
# plot(t(allD[1, -ncol(allD)]), t(allD[i,-ncol(allD)]), main=allD[i,ncol(allD)], ylab="method", xlab="FACS")
# text(min(t(allD[1, -ncol(allD)]), na.rm=T)*2, max(t(allD[i, -ncol(allD)]), na.rm=T), paste("r=", round(a1, digits=2), sep=""))
}
cell_type=paste(testSetB[j], allD$method, sep="_all_")
MergedTable=rbind(MergedTable, cbind(cell_type, allD[ ,-21]))
}
CorMatAll=rbind(CMat, savTemp)
CorMatP=rbind(PMat, savTempP)
par(oma=c(2, 0,0,5))
heatmap.2(CorMatAll, col=RdBu[11:1], scale="none", trace="none", main="correlation FACS and GE")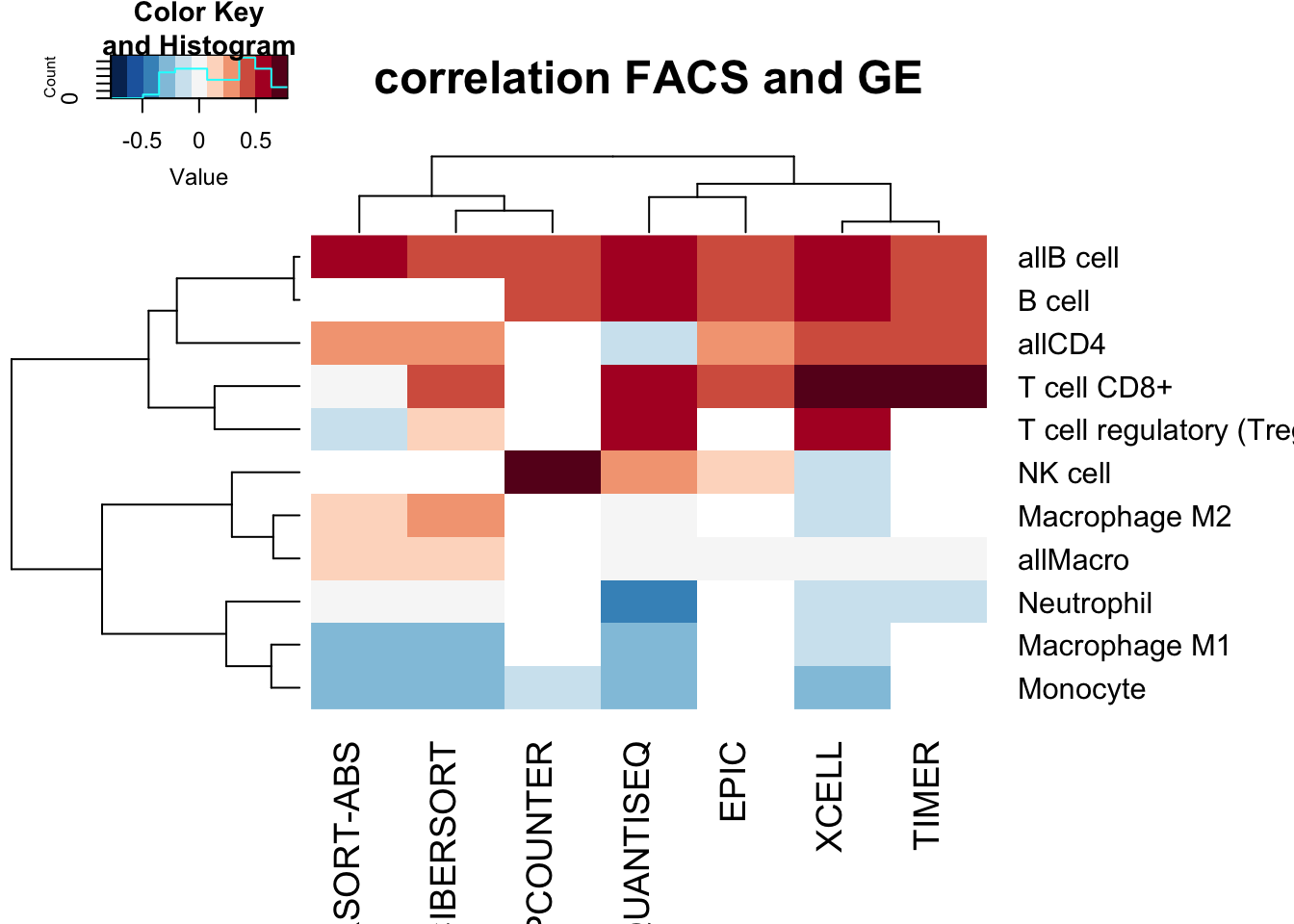
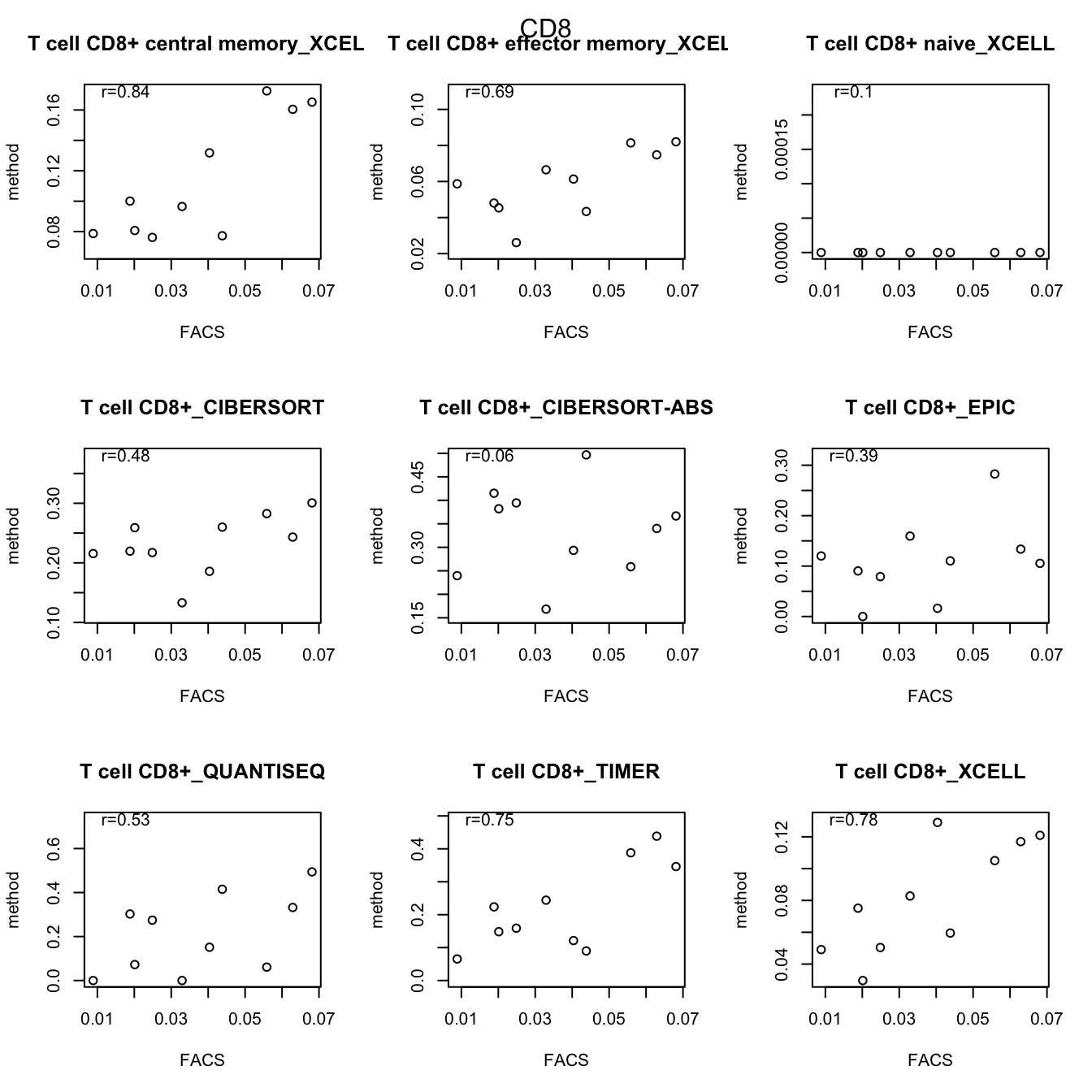
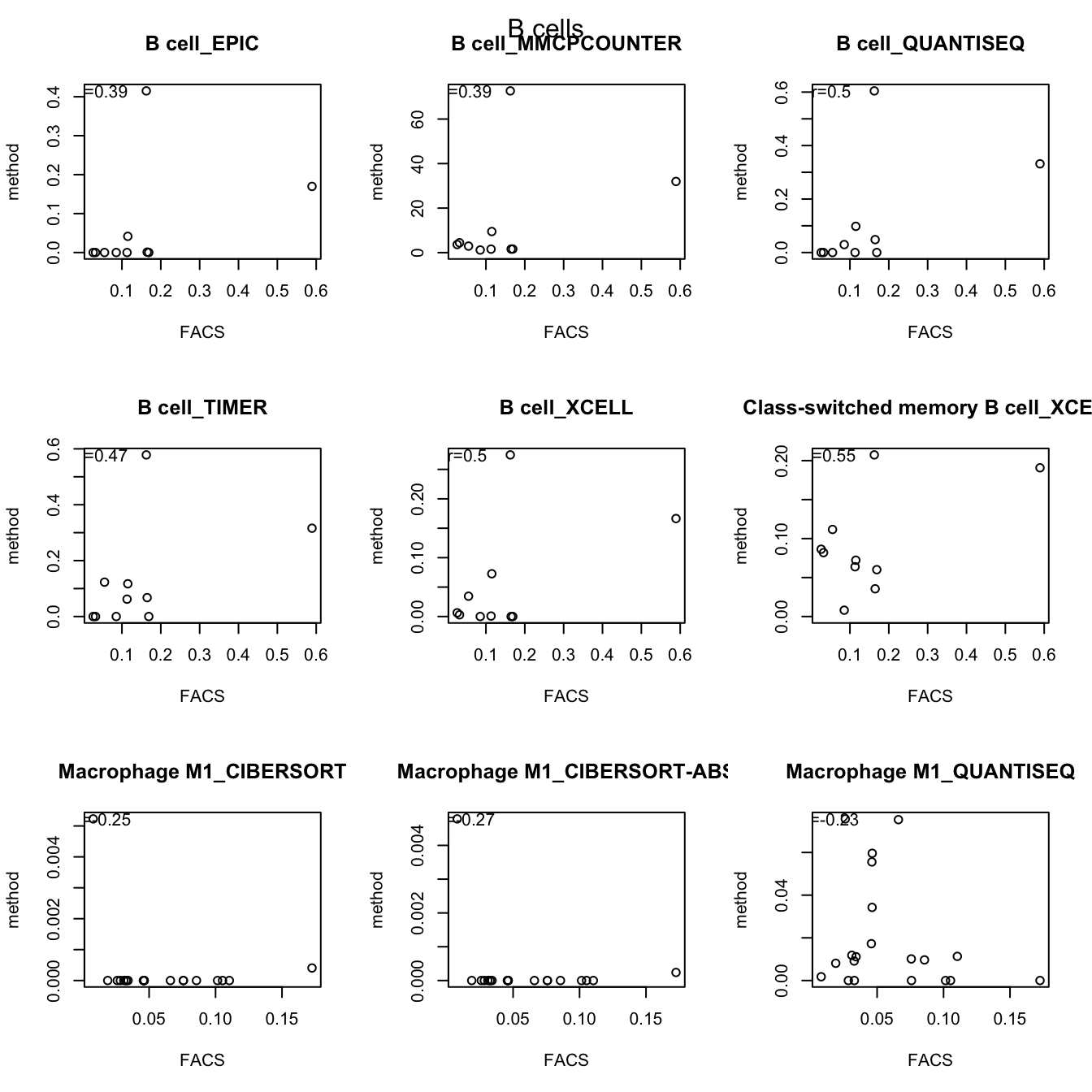
We can plot associations between the different cell types below, here selecting:
- Bcells
- CD8 T cells
- M2 macophage
- M1 macrophage
with each method. The correlation coefficient is indicated.
testSetB=c("CD8", "B cells", "MHCII-hi", "MHCII-lo")
testSet=c("CD8", "B cell","M1", "M2")
par(mfrow=c(3,3))
for (j in 1:length(testSetB)){
CMat=matrix(NA, ncol=length(testSet), nrow=10)
CD8Table=rbind(lx1[grep(testSetB[j], lx1$cell_type), ],
out2[grep(testSet[j], out2$cell_type), ])
for (i in 2:nrow(CD8Table)){
a1=cor(t(CD8Table[1, -1]), t(CD8Table[i, -1]), use="complete")
plot(t(CD8Table[1, -1]), t(CD8Table[i, -1]), main=CD8Table[i,1], ylab="method", xlab="FACS")
text(min(t(CD8Table[1, -1]), na.rm=T)*2, max(t(CD8Table[i, -1]), na.rm=T), paste("r=", round(a1, digits=2), sep=""))
}
mtext(testSetB[j], side=3, line=-2, outer=T)
}

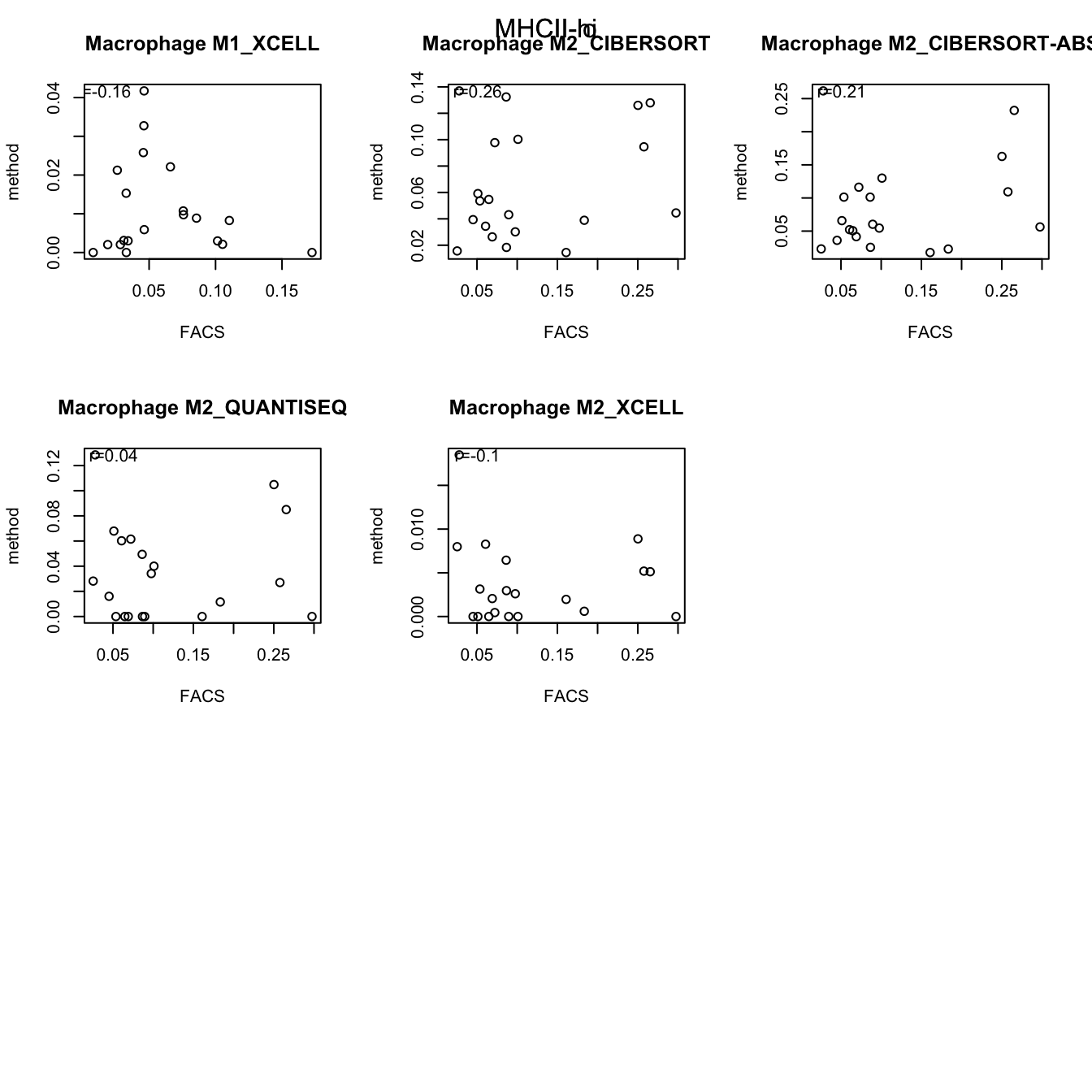
19.4 Progression cohort
We perform the same sort of analysis for the progression cohort:
# drop samples
#dsamp=c("2R_D_CD45", "3L_D_CD45")
sizeInfo=infoTableFinal$GrowthRate[match(colnames(ProgSpecCD45)[-1], rownames(infoTableFinal))]
#sizeInfo=Cdata$GrowthRate[match(substr(colnames(ProgSpecCD45)[-1], 1, nchar(colnames(ProgSpecCD45)[-1])-5), Cdata$TumorID)]
CorVals=rep(NA, nrow(ProgSpecCD45))
names(CorVals)=ProgSpecCD45$cell_type
CorValsP=CorVals
CorVals=sapply(1:nrow(ProgSpecCD45), function(x) cor(t(ProgSpecCD45[x, -1]), sizeInfo, use="complete"))
CorValsP=sapply(1:nrow(ProgSpecCD45), function(x) cor.test(t(ProgSpecCD45[x, -1]), sizeInfo, use="complete")$p.value)
naidx=which(CorValsP<0.05)
RNames1=sapply(strsplit(ProgSpecCD45$cell_type, "_"), function(x) x[1])
RNamesMethod=sapply(strsplit(ProgSpecCD45$cell_type, "_"), function(x) x[2])
df2=data.frame(cell=RNames1, method=RNamesMethod, cor=CorVals, p=CorValsP)
ax1=acast(df2[ ,c(1:3)], RNames1~RNamesMethod)
#df2=data.frame(cell=RNames1, method=RNamesMethod, cor=CorValsP)
ax2=acast(df2[ ,c(1:2,4)], RNames1~RNamesMethod)
ax2[which(ax2>0.05, arr.ind=T)]=0
ax2[which(is.na(ax2), arr.ind = T)]=0
#pdf("~/Desktop/4F_progression_association_growthrate_all_methods.pdf", width=8, height=6)
par(oma=c(2, 2, 2, 2))
OutputplotFun(ax1, scaleR="none", main="cell type correlation", classN="no", sigMat=ax2)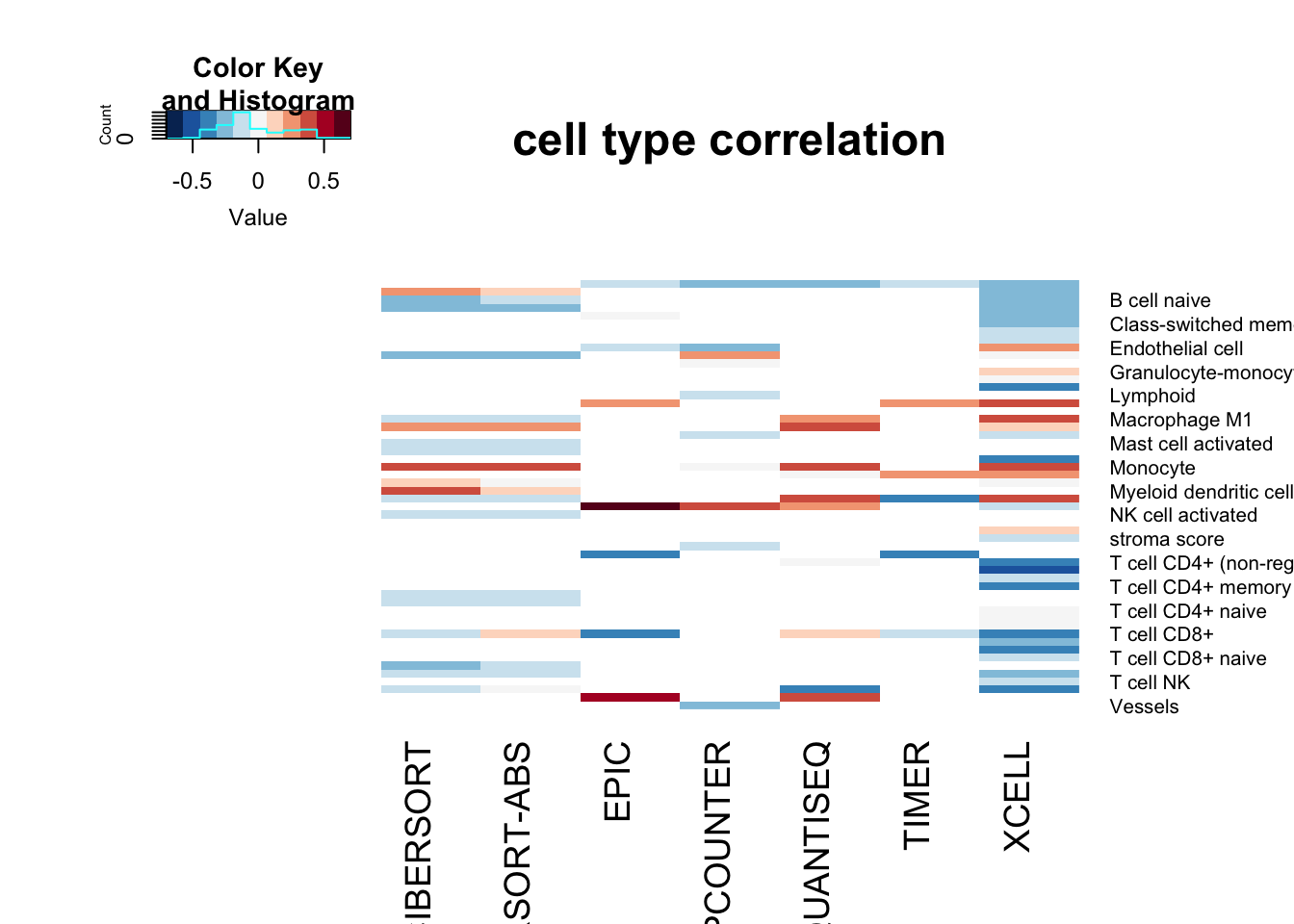
#dev.off()
## Also plot these all separately
sizeInfoCut=infoTableFinal$Growth[match(colnames(ProgSpecCD45)[-1], rownames(infoTableFinal))]
#sizeInfoCut=ifelse(sizeInfo>=2, "growing", "stable")
ttestP=sapply(1:nrow(ProgSpecCD45), function(x) wilcox.test(t(ProgSpecCD45[x, -1])~sizeInfoCut)$p.value)
ttestVal=sapply(1:nrow(ProgSpecCD45), function(x) diff(t.test(t(ProgSpecCD45[x, -1])~sizeInfoCut)$est))
df3=data.frame(cell=RNames1, method=RNamesMethod, val=ttestVal, p=ttestP)
ax3=acast(df3[ ,c(1:2, 4)], RNames1~RNamesMethod)
ax3[which(ax3>0.05, arr.ind=T)]=0
ax3[which(is.na(ax3), arr.ind = T)]=0
ax4=acast(df3[ ,c(1:3)], RNames1~RNamesMethod)
#pdf("~/Desktop/4F_progression_association_growth_types.pdf", width=8, height=5)
par(mfrow=c(2,2))
for (i in 1:ncol(ax1)){
t1=ax1[, i]
t2=which(!is.na(t1))
image(cbind(ax4[t2, i],ax4[t2, i]), col=RdBu[11:1], xaxt="none", yaxt="none",
main=sprintf("correlation %s (* sig p<0.05)", colnames(ax1)[i]))
axis(1, at=seq(0, 1, length=length(t2)), names(t1)[t2], las=2, cex=0.7)
axis(2, at=c(0,1),c("cor p", "wilcox p"), las=2, cex=0.7)
mx=which(ax2[ t2,i]>0)
text((mx-1)/(length(t2)-1), 0 , "*")
mx=which(ax3[ t2,i]>0)
text((mx-1)/(length(t2)-1), 1 , "*")
}
#write.csv(df2, file="nature-tables/4f.csv")
DT::datatable(df3, rownames=F, class='cell-border stripe',
extensions="Buttons", options=list(dom="Bfrtip", buttons=c('csv', 'excel')))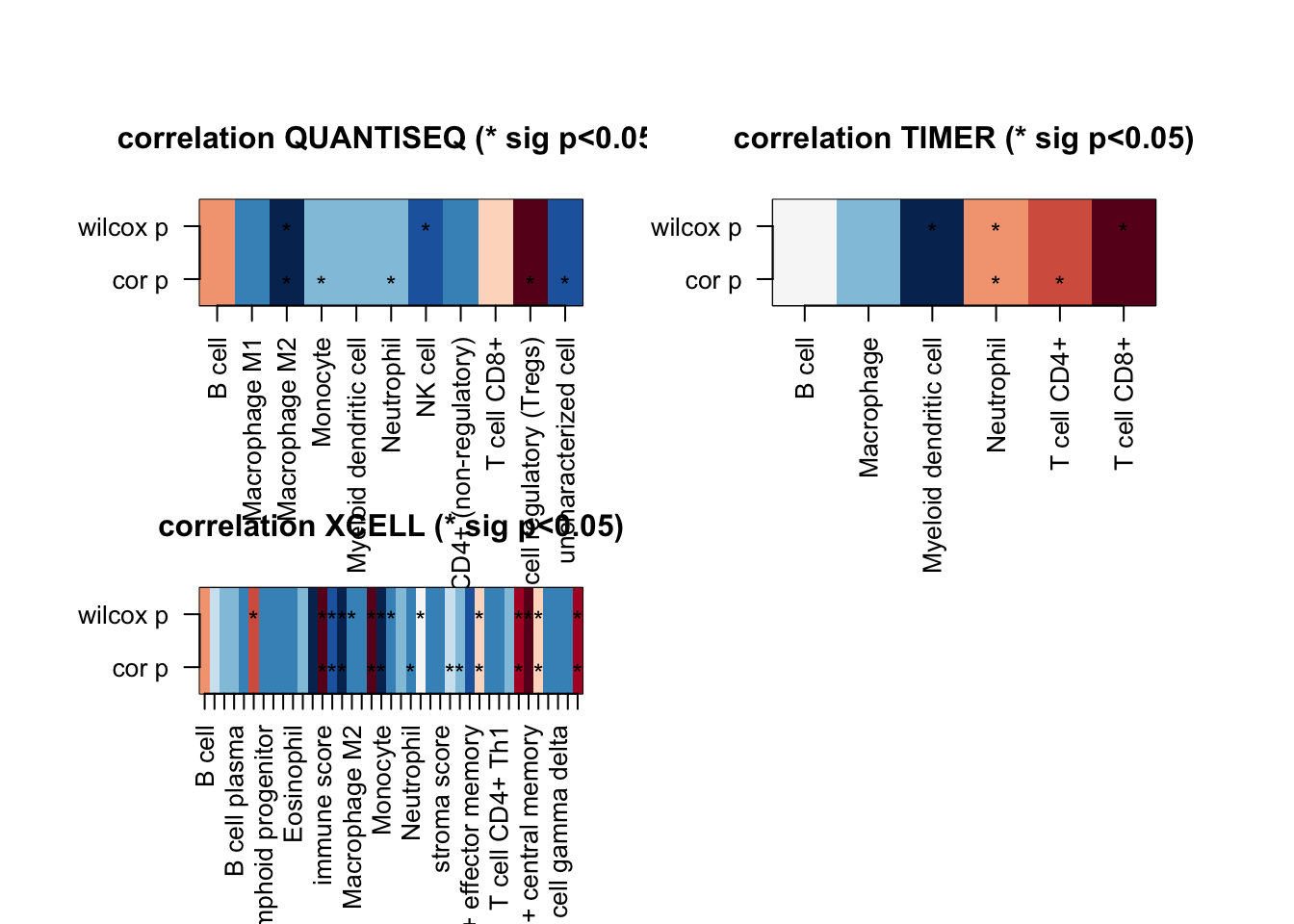
Make the plots with individual samples. Firstly TIMER
#pdf("~/Desktop/4F-sample-celltypes-arranged_by_growth_rate.pdf", height=6, width=10)
x2=c(colnames(ProgSpecCD45)[order(sizeInfo)+1])
ax1=grep("TIMER", ProgSpecCD45$cell_type)
T1melt=melt(ProgSpecCD45[ax1, ])
T1melt$growth=infoTableFinal$Growth[match(T1melt$variable, infoTableFinal$SampleID)]
T1melt$treatment=infoTableFinal$Treatment[match(T1melt$variable, infoTableFinal$SampleID)]
T1melt$variable=factor(T1melt$variable, x2)
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type))+geom_bar(stat="identity")+facet_grid(~growth, space="free_x", scale="free", drop=T)+ggtitle("TIMER:prog growth")+theme(axis.text.x = element_text(angle = 90))+
scale_fill_manual(values=c("#66C2A5", "#FED976", "#FEEBE2" ,"#AE017E", "#2171B5", "#BDD7E7", "#EFF3FF"))+theme_bw()+theme(axis.text.x = element_text(angle = 90))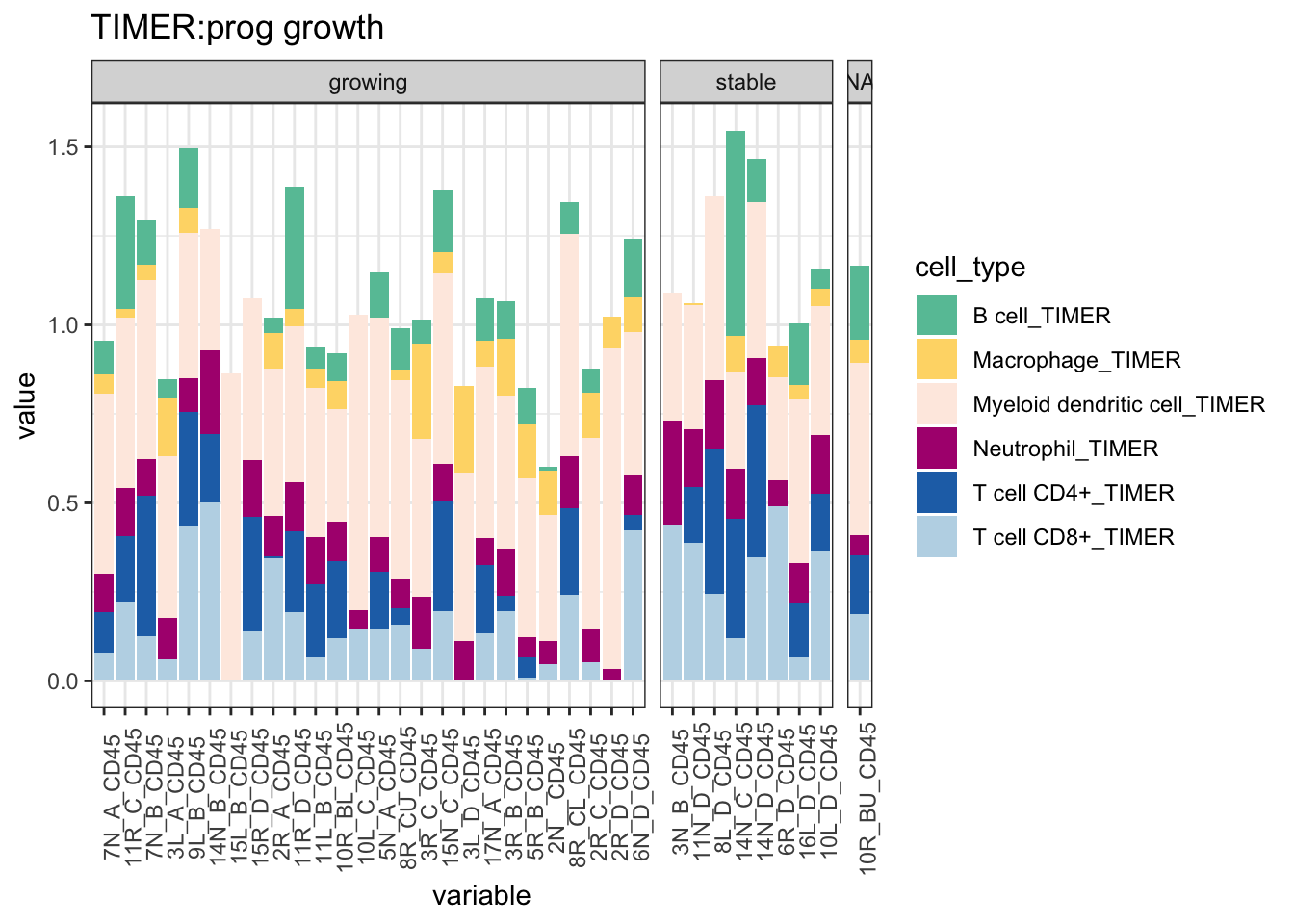
Figure 19.5: Progression CIBERSORT TIMER
then CIBERSORT
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type))+geom_bar(stat="identity")+facet_grid(~treatment, space="free_x", scale="free", drop=T)+ggtitle("TIMER:prog treatment")+theme(axis.text.x = element_text(angle = 90))+
scale_fill_manual(values=c("#66C2A5", "#FED976", "#FEEBE2" ,"#AE017E", "#2171B5", "#BDD7E7", "#EFF3FF"))+theme_bw()+theme(axis.text.x = element_text(angle = 90))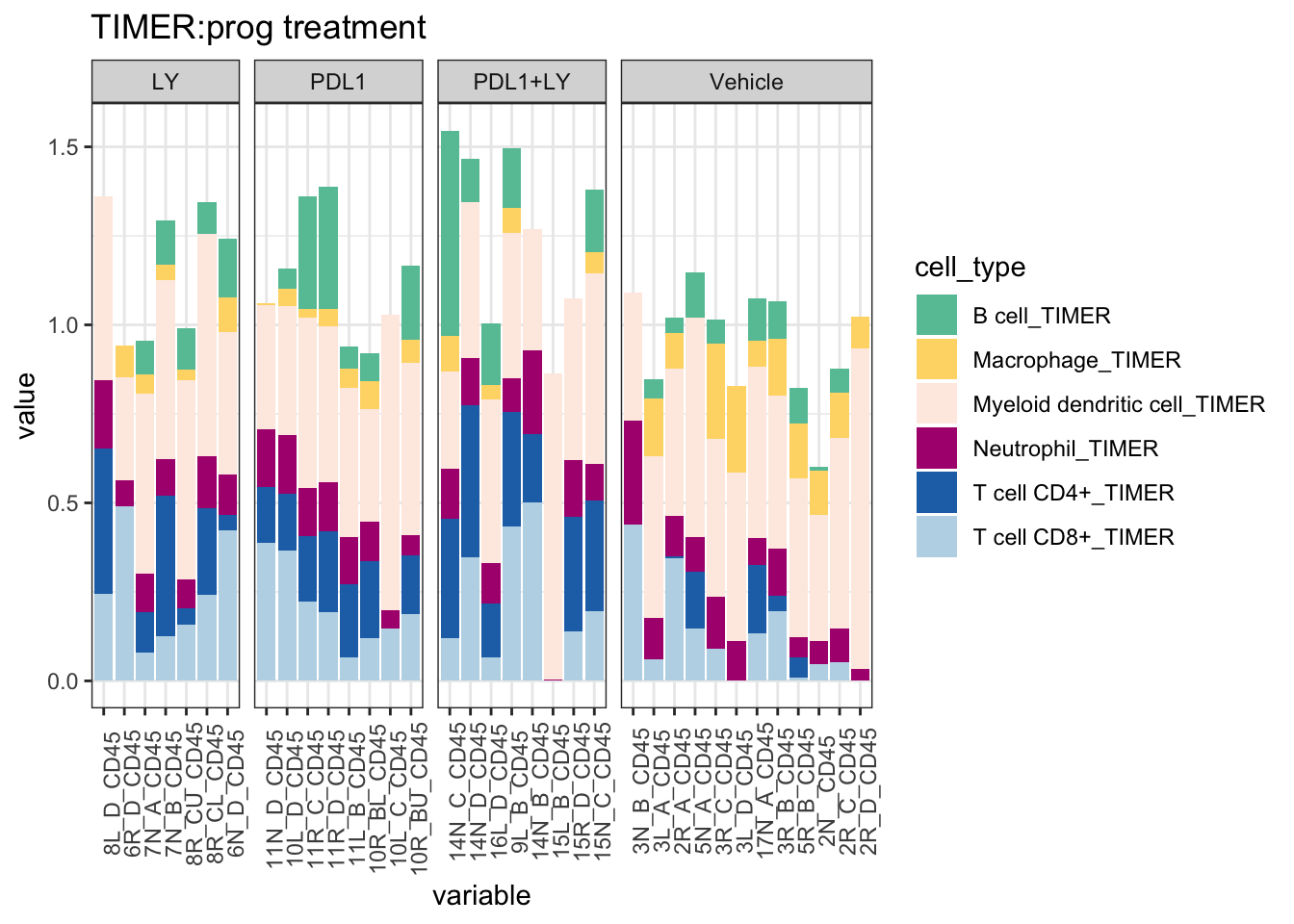
ax1=grep("CIBERSORT$", ProgSpecCD45$cell_type)
T1melt=melt(ProgSpecCD45[ax1, ])
T1melt$variable=factor(T1melt$variable, x2)
T1melt$growth=infoTableFinal$Growth[match(T1melt$variable, infoTableFinal$SampleID)]
T1melt$treatment=infoTableFinal$Treatment[match(T1melt$variable, infoTableFinal$SampleID)]
pdf("~/Desktop/newFigure4.pdf", height=10, width=15)
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type))+geom_bar(stat="identity")+facet_grid(~growth, space="free_x", scale="free")+
ggtitle("CIBSERT:char cohort separately")+theme(axis.text.x = element_text(angle = 90))+theme_bw()+
theme(axis.text.x = element_text(angle = 90))+scale_fill_manual(values=c("#F8766D",
"#EC8239",
"#DB8E00",
"#C79800",
"#AEA200",
"#8FAA00",
"#A1B72C",
"#5E5E5E",
"#64B200",
"#00BD5C",
#"#E6F0ED",
"#00C1A7",
"#00BFC4",
"#00BADE",
"#CB5C5A",
"#FFAD00",
"#FF0B00",
"#B385FF",
"#D874FD",
"#EF67EB",
"#FFA9AD",
"#FF63B6",
"#FF6B94"))
dev.off()
## quartz_off_screen
## 2
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type))+geom_bar(stat="identity")+facet_grid(~treatment, space="free_x", scale="free")+
ggtitle("CIBSERT:char cohort separately")+theme(axis.text.x = element_text(angle = 90))+theme_bw()+
theme(axis.text.x = element_text(angle = 90))
# Also do a version where the Bcells, Macrophages,NK, Mast Cells, CD4, CD8 Cells are merged together, NK
T1melt$cell_type2=substr(T1melt$cell_type, 1, 4)
T1melt$cell_type2[grep("CD8", T1melt$cell_type)]="T CD8"
T1melt$cell_type2[grep("CD4", T1melt$cell_type)]="T CD4"
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type2))+geom_bar(stat="identity")+facet_grid(~growth, space="free_x", scale="free")+
ggtitle("CIBSERT:prog growth")+theme(axis.text.x = element_text(angle = 90))+
scale_fill_manual(values=c("#66C2A5", "#E6F598", "#FED976", "#FC4E2A", "#bdbdbd", "#FEEBE2" ,"#AE017E", "#5E4FA2", "#2171B5", "#BDD7E7", "#EFF3FF"))+theme_bw()+theme(axis.text.x = element_text(angle = 90))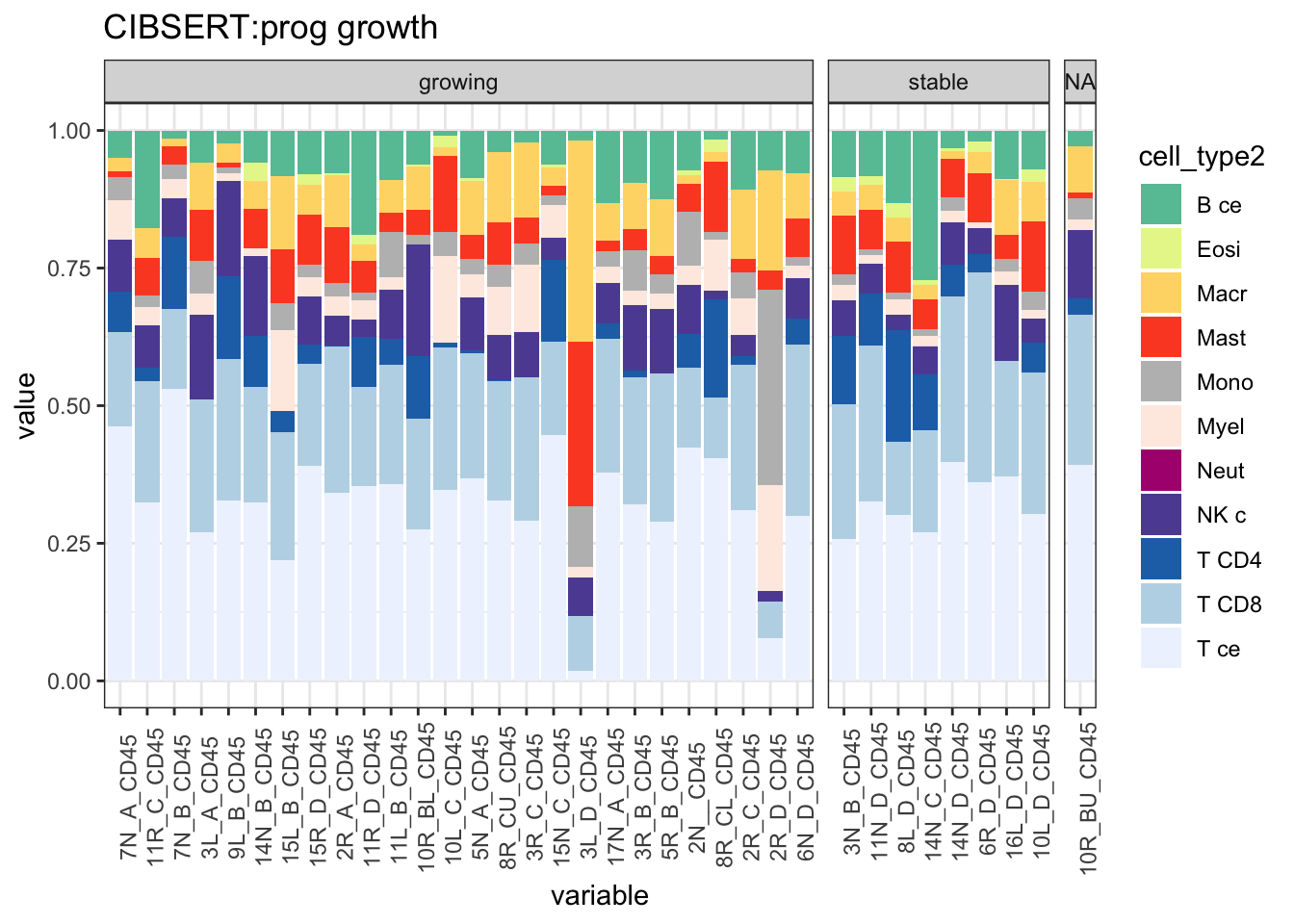
ggplot(T1melt, aes(x=variable, y=value, fill=cell_type2))+geom_bar(stat="identity")+facet_grid(~treatment, space="free_x", scale="free")+
ggtitle("CIBSERT:prog treatment")+theme(axis.text.x = element_text(angle = 90))+
scale_fill_manual(values=c("#66C2A5", "#E6F598", "#FED976", "#FC4E2A", "#bdbdbd", "#FEEBE2" ,"#AE017E", "#5E4FA2", "#2171B5", "#BDD7E7", "#EFF3FF"))+theme_bw()+theme(axis.text.x = element_text(angle = 90))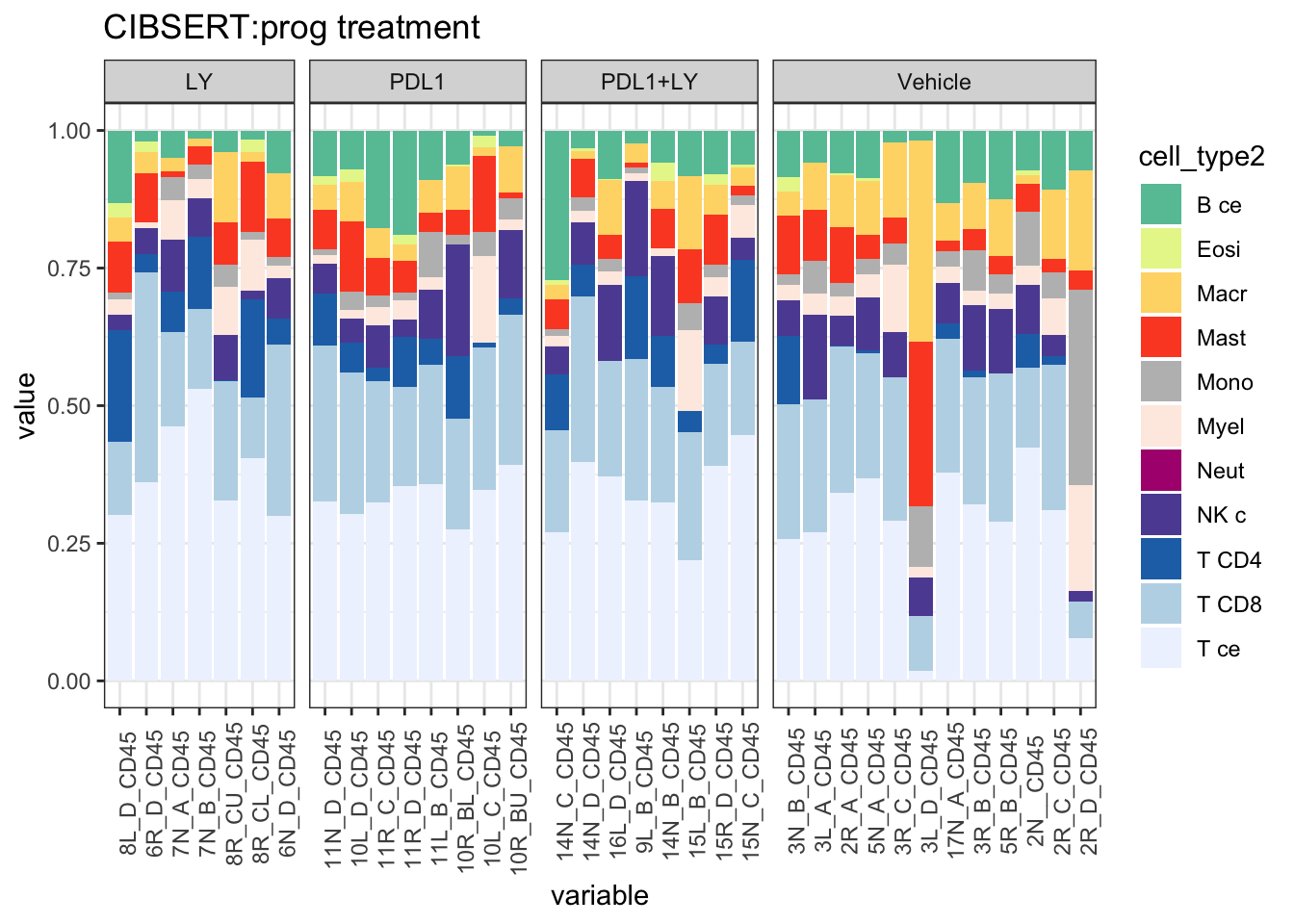
T1melt$sdat=paste(T1melt$variable, T1melt$cell_type2, sep=".")
T2=by(T1melt$value, T1melt$sdat, sum)
T2m=stack(T2)
T2m$ind1=sapply(strsplit(as.character(T2m$ind), "\\."), function(x) x[1])
T2m$ind2=sapply(strsplit(as.character(T2m$ind), "\\."), function(x) x[2])
T2mTab=acast(T2m[ ,c(1, 3:4)], ind2~ind1, value.var="values")
CorV=sapply(1:nrow(T2mTab), function(x) cor(T2mTab[x, ], sizeInfo, use="complete"))
CorVP=sapply(1:nrow(T2mTab), function(x) cor.test(T2mTab[x, ], sizeInfo, use="complete")$p.value)
wilP=sapply(1:nrow(T2mTab), function(x) wilcox.test(T2mTab[x, ]~ sizeInfoCut)$p.value)
# image(cbind(CorV,CorV), col=RdBu[11:1], xaxt="none", yaxt="none",
# main="correlation CIBERSORT growth rate (* sig p<0.1)")
# axis(1, at=seq(0, 1, length=length(CorV)), rownames(T2mTab), las=2, cex=0.7)
# axis(2, at=c(0,1),c("cor p", "wilcox p"), las=2, cex=0.7)
# mx=which(CorVP<0.1)
# text((mx-1)/(CorVP-1), 0 , "*")
# mx=which(wilP<0.1)
# text((mx-1)/(wilP-1), 1 , "*")
#dev.off()
#write.csv(T1melt, file="nature-tables/4f_image.csv")
DT::datatable(T1melt, rownames=F, class='cell-border stripe',
extensions="Buttons", options=list(dom="Bfrtip", buttons=c('csv', 'excel')))19.5 Clinical associations
19.5.1 Associate with Treatment
Look at association with treatment, growth and spatial infiltration for each method.
Associations with treatment:
- higher CD4, CD8 in most treatments
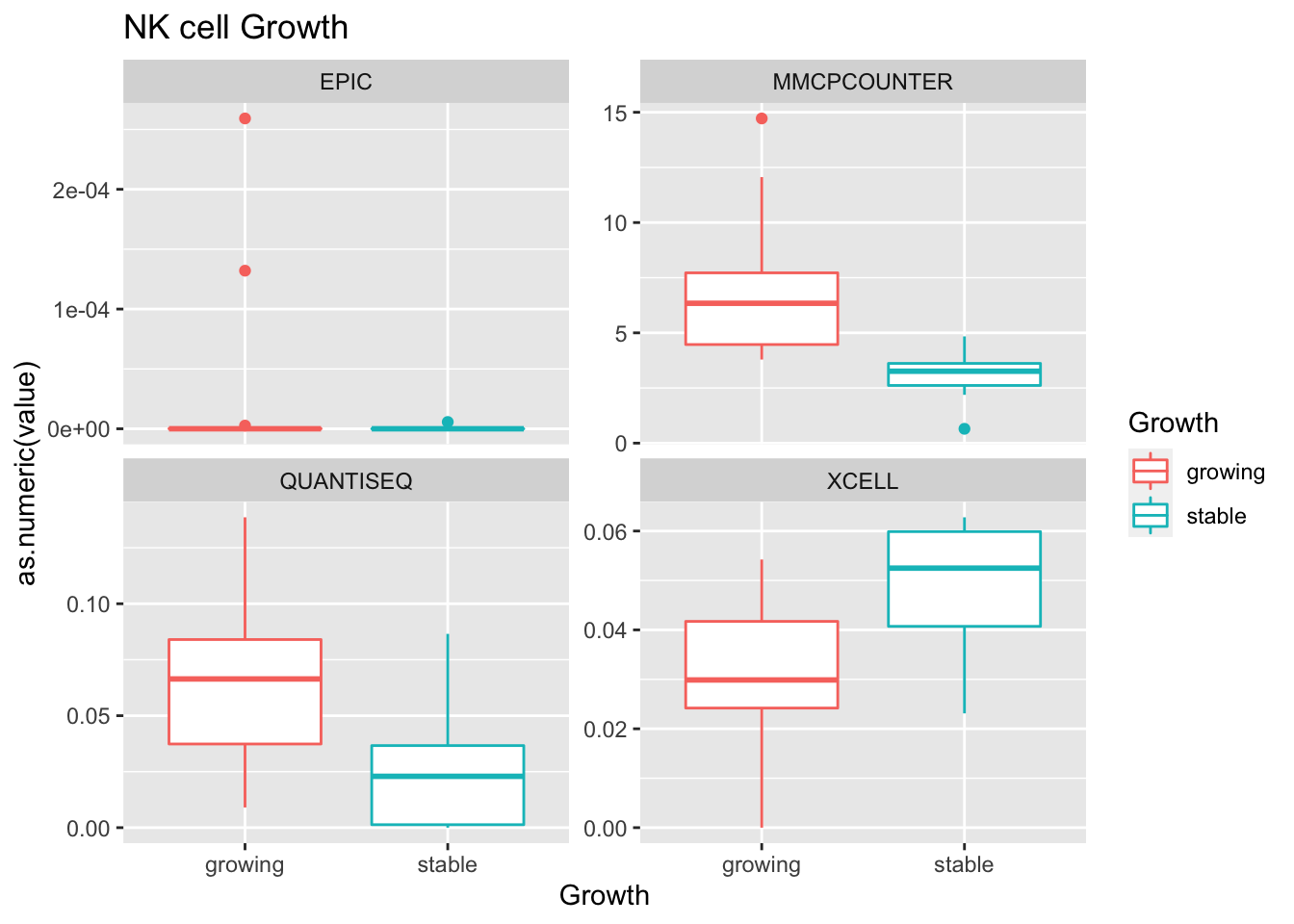
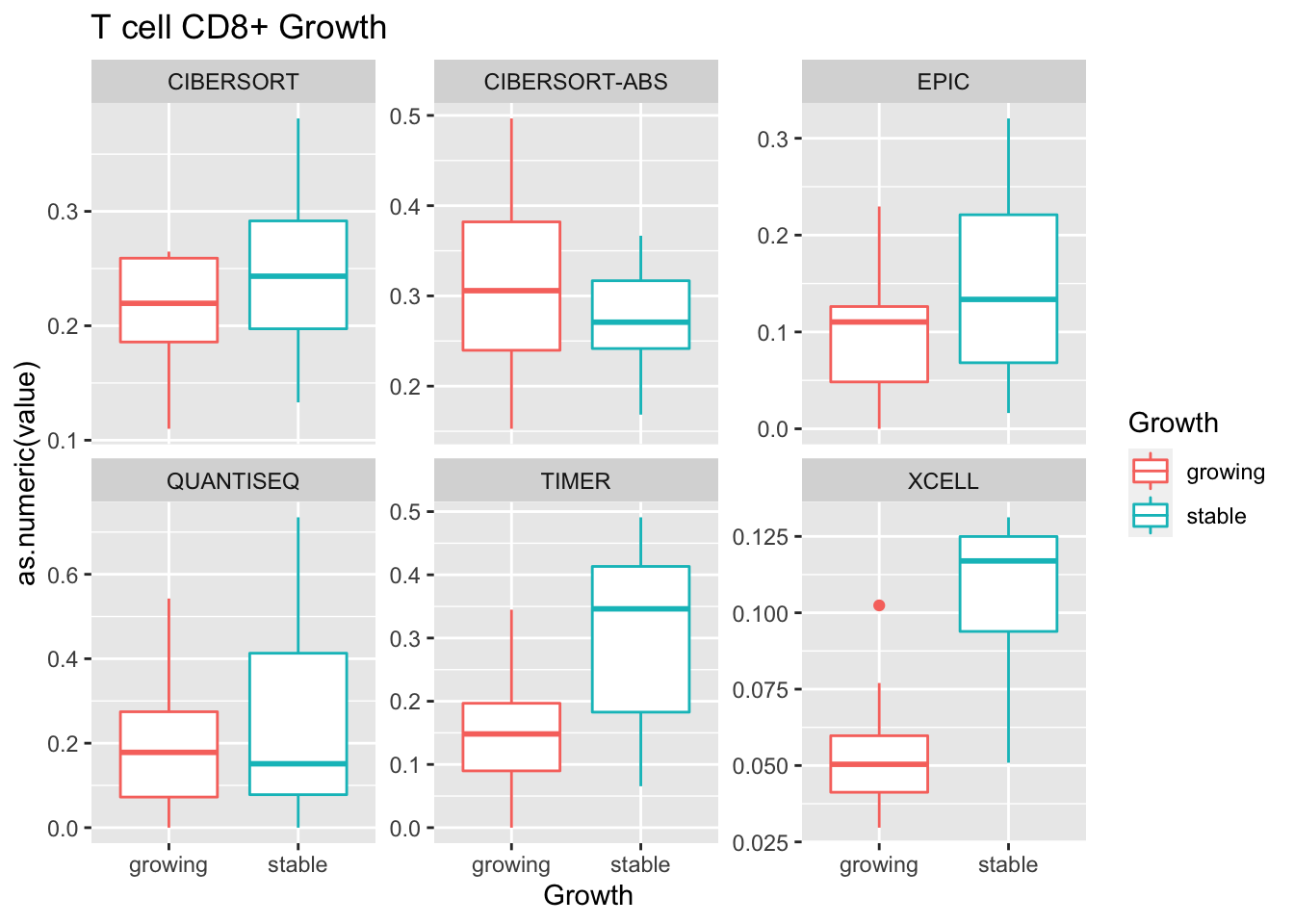
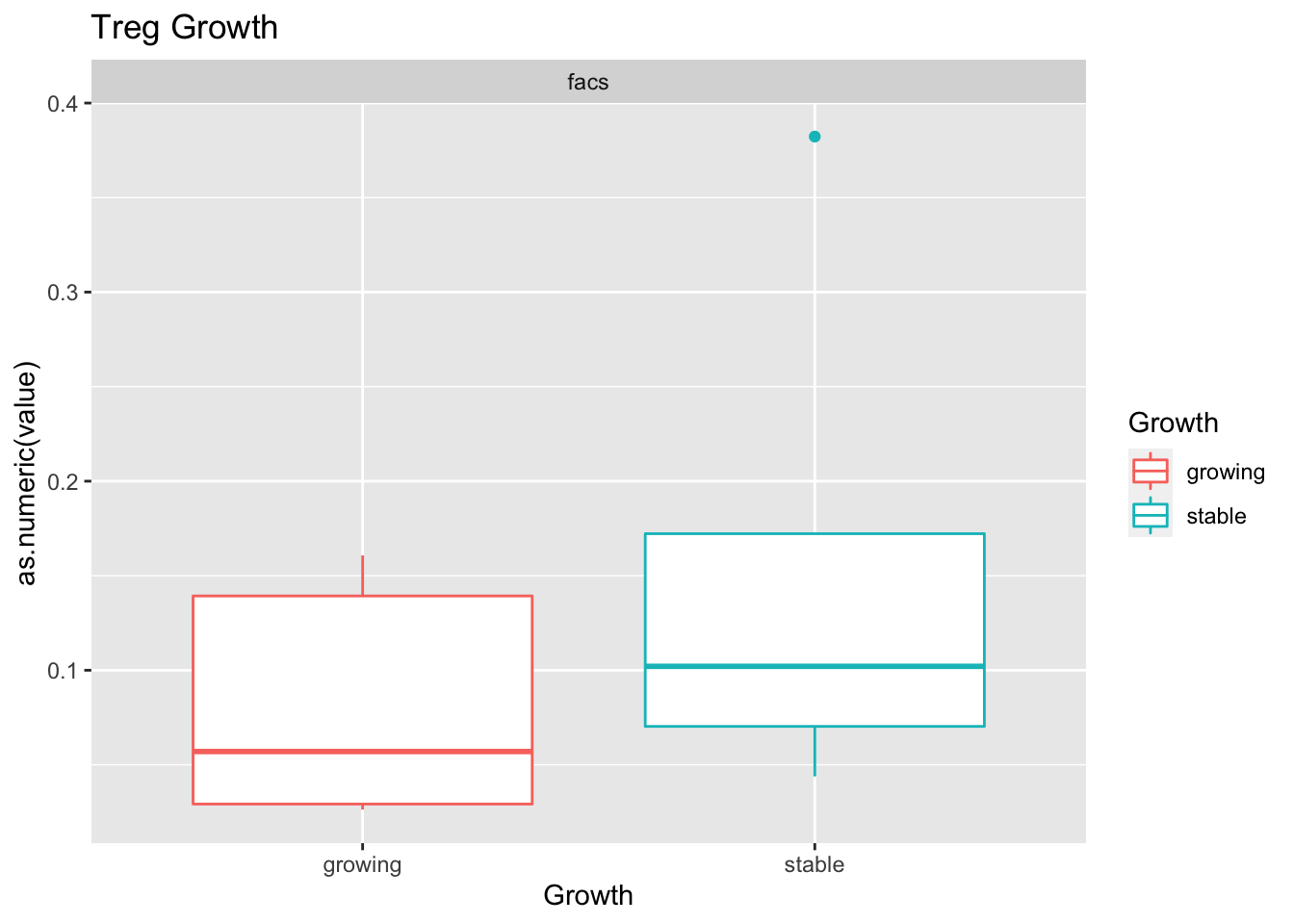
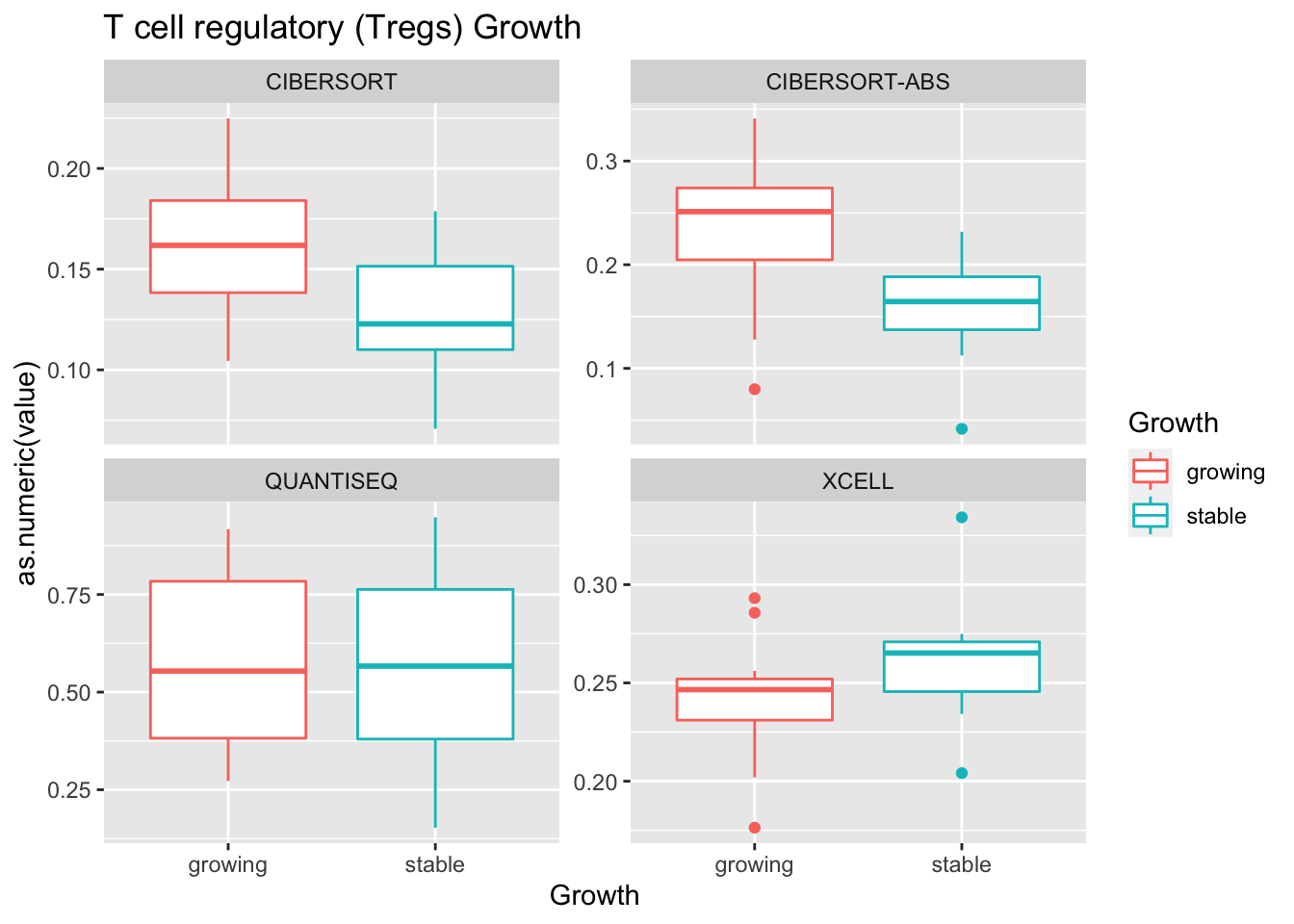
- growth: stable associated with higher CD8
- infiltration: more neutrophils and CD8? maybe CD4 cells
#sizeCutOff=7
MergedTablemelt=melt(MergedTable[-1, ])
MergedTablemelt$Treatment=infoTableFinal$Treatment[match(MergedTablemelt$variable, infoTableFinal$SampleID)]
MergedTablemelt$Growth=infoTableFinal$Growth[match(MergedTablemelt$variable, infoTableFinal$SampleID)]
MergedTablemelt$InfRes=infoTableFinal$MHcut[match(MergedTablemelt$variable, infoTableFinal$SampleID)]
MergedTablemelt$cell_type2=sapply(strsplit(MergedTablemelt$cell_type, "_"), function(x) x[1])
MergedTablemelt$method=sapply(strsplit(MergedTablemelt$cell_type, "_"), function(x) x[length(x)])
unValues=unique(MergedTablemelt$cell_type2)
CompTest=list()
for (i in 1:length(unValues)){
ax=MergedTablemelt[MergedTablemelt$cell_type2==unValues[i], ]
p<-ggplot(ax, aes(x=Treatment, y=as.numeric(value), col=Treatment))+geom_boxplot()+facet_wrap(~method, scale="free_y")+ggtitle(paste(unValues[i], "Treatment"))
print(p)
#p<-ggplot(ax, aes(x=Growth, y=as.numeric(value), col=Growth))+geom_boxplot()+facet_wrap(~method, scale="free_y")+ggtitle(paste(unValues[i], "Growth"))
#print(p)
#p<-ggplot(ax, aes(x=InfRes, y=as.numeric(value), col=InfRes))+geom_boxplot()+facet_wrap(~method, #scale="free_y")+ggtitle(paste(unValues[i], "Infiltration"))
#print(p)
unT=sort(unique(ax$Treatment))
unB=sort(unique(ax$method))
Outcome1=matrix(NA, nrow=5, ncol=length(unB))
rownames(Outcome1)=c(paste(unT[1:3], "vs.Vehicle", sep=""), "Grow.Stable", "Inf.res")
colnames(Outcome1)=unB
for (j in 1:nrow(Outcome1)){
Outcome1[1 , ]=sapply(unB, function(x) wilcox.test(ax$value[which(ax$Treatment=="LY" & ax$method==x)],
ax$value[ax$Treatment=="Vehicle" & ax$method==x])$p.value)
Outcome1[2 , ]=sapply(unB, function(x) wilcox.test(ax$value[ax$Treatment=="PDL1" & ax$method==x],
ax$value[ax$Treatment=="Vehicle" & ax$method==x])$p.value)
Outcome1[3 , ]=sapply(unB, function(x) wilcox.test(ax$value[ax$Treatment=="PDL1+LY" & ax$method==x],
ax$value[ax$Treatment=="Vehicle" & ax$method==x])$p.value)
Outcome1[4 , ]=sapply(unB, function(x) wilcox.test(ax$value[ax$Growth=="growing" & ax$method==x],
ax$value[ax$Growth=="stable" & ax$method==x])$p.value)
Outcome1[5 , ]=sapply(unB, function(x) wilcox.test(ax$value[ax$InfRes=="inf" & ax$method==x],
ax$value[ax$InfRes=="res" & ax$method==x])$p.value)
}
CompTest[[i]]=t(Outcome1)
o1=Outcome1
o1[which(o1<0.05, arr.ind=T)]=3
o1[which(o1<0.1, arr.ind=T)]=2
o1[which(o1<=1, arr.ind=T)]=0
#heatmap.2(o1, col=brewer.pal(9, "Blues"), scale="none", trace="none", main=paste("pvalue summary", unValues[i]), Colv = NA, Rowv = NA)
}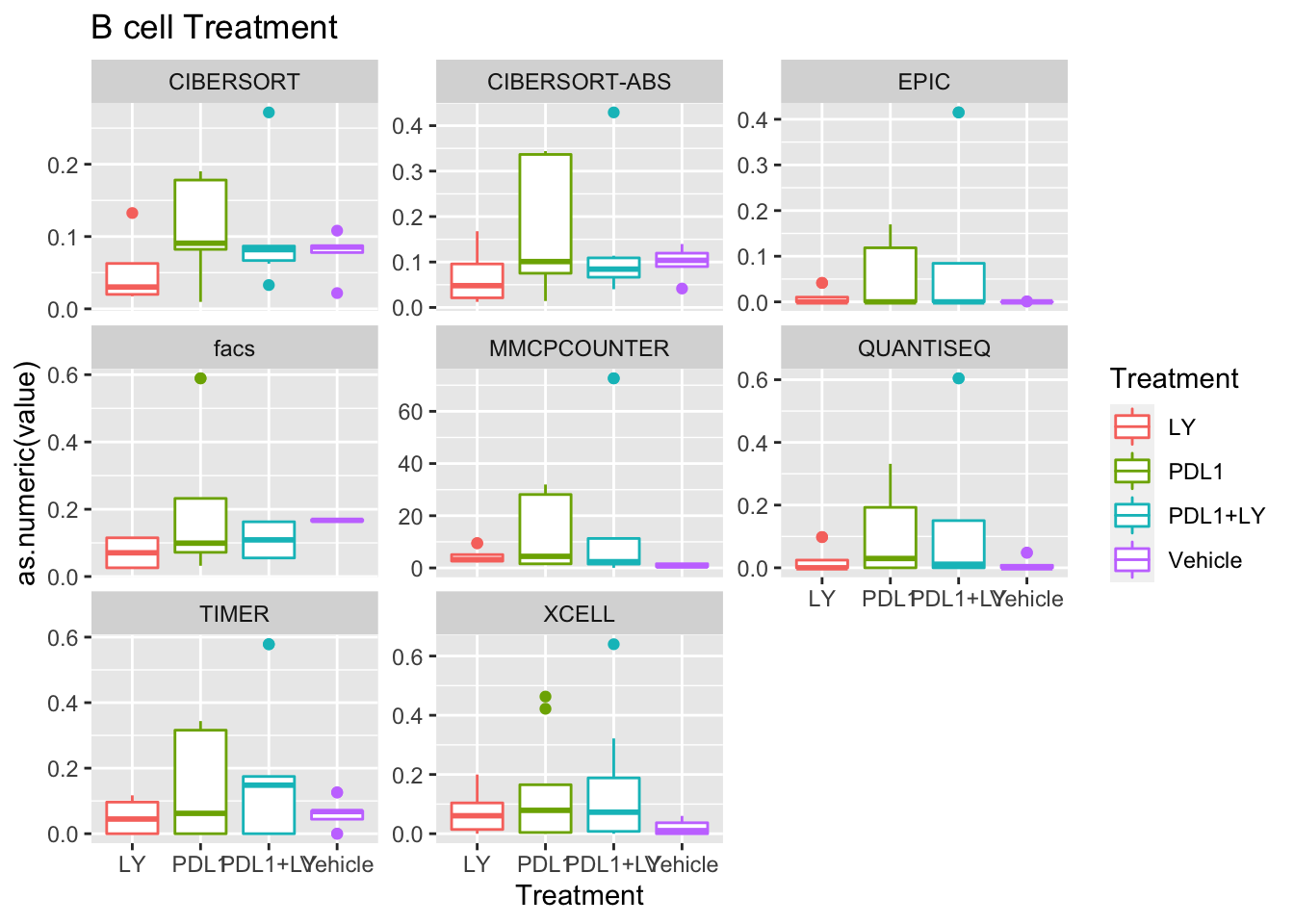
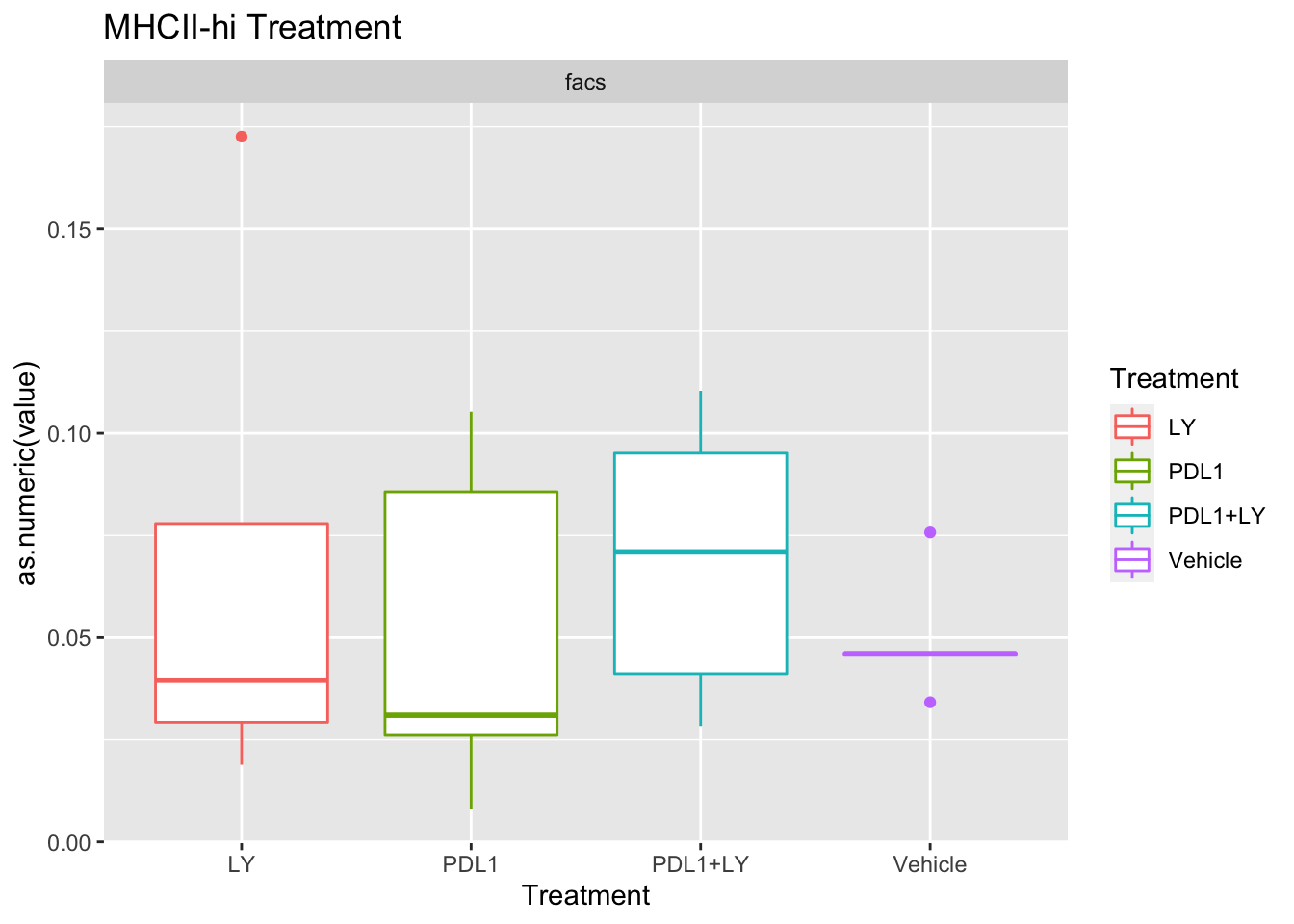
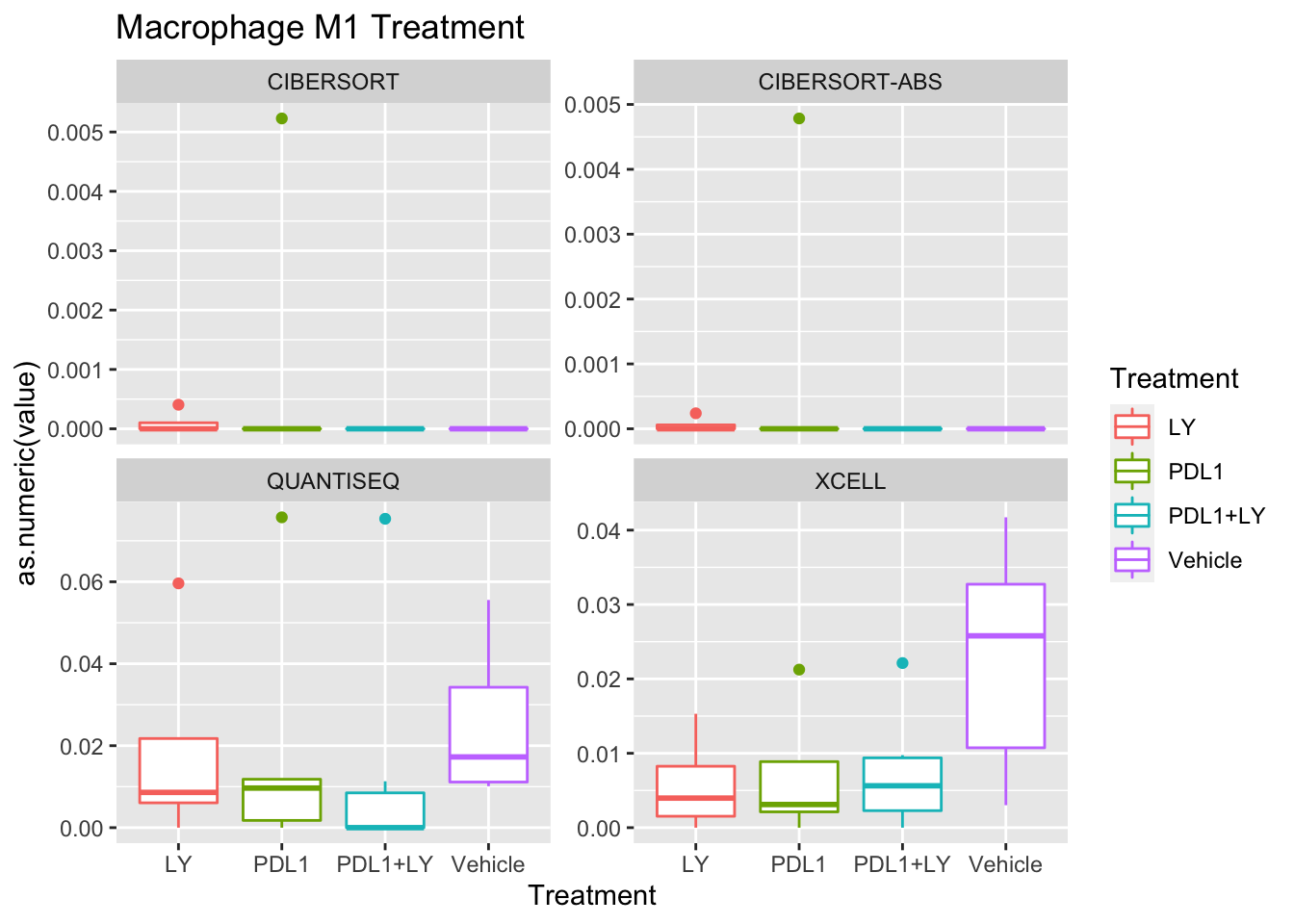
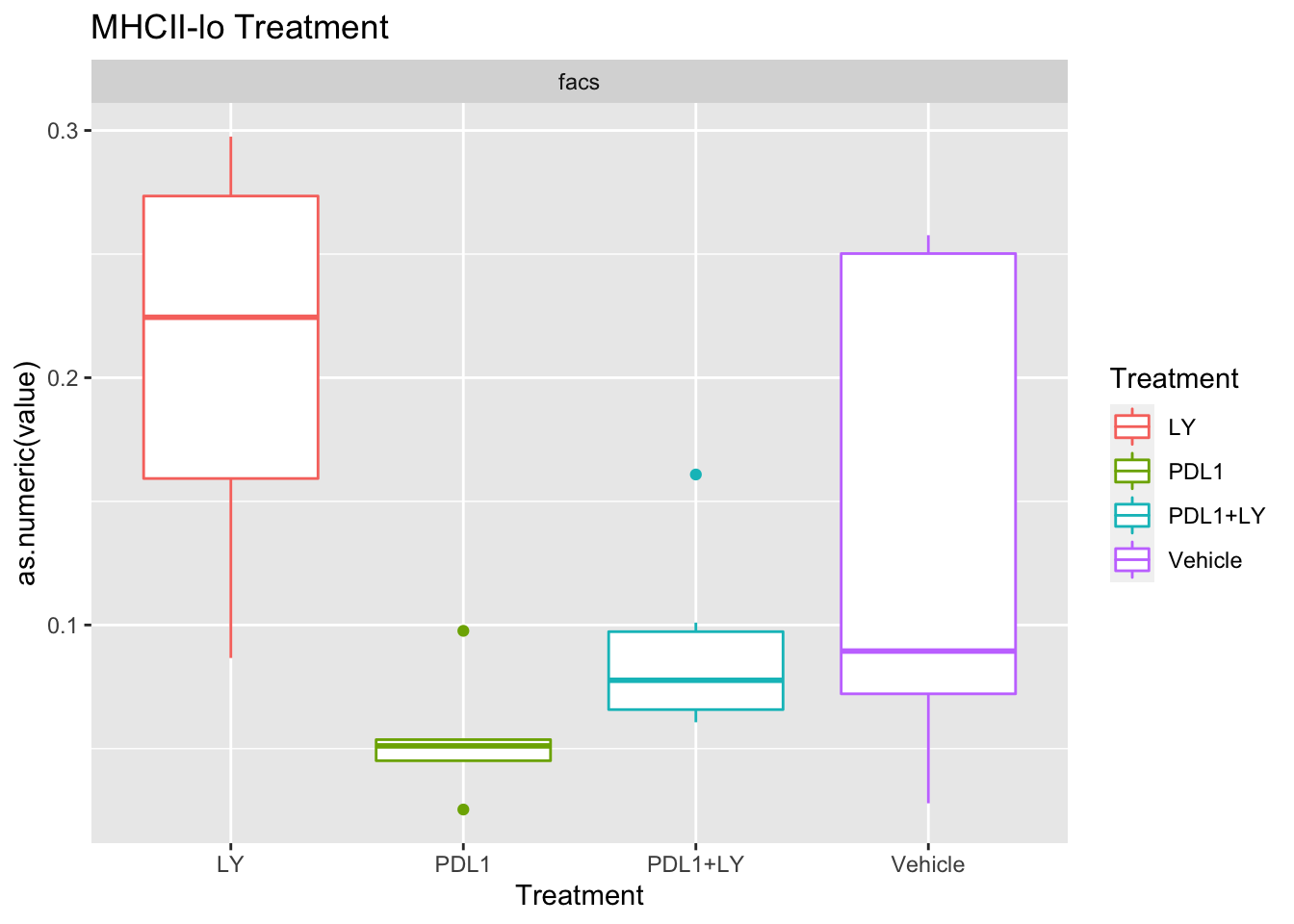
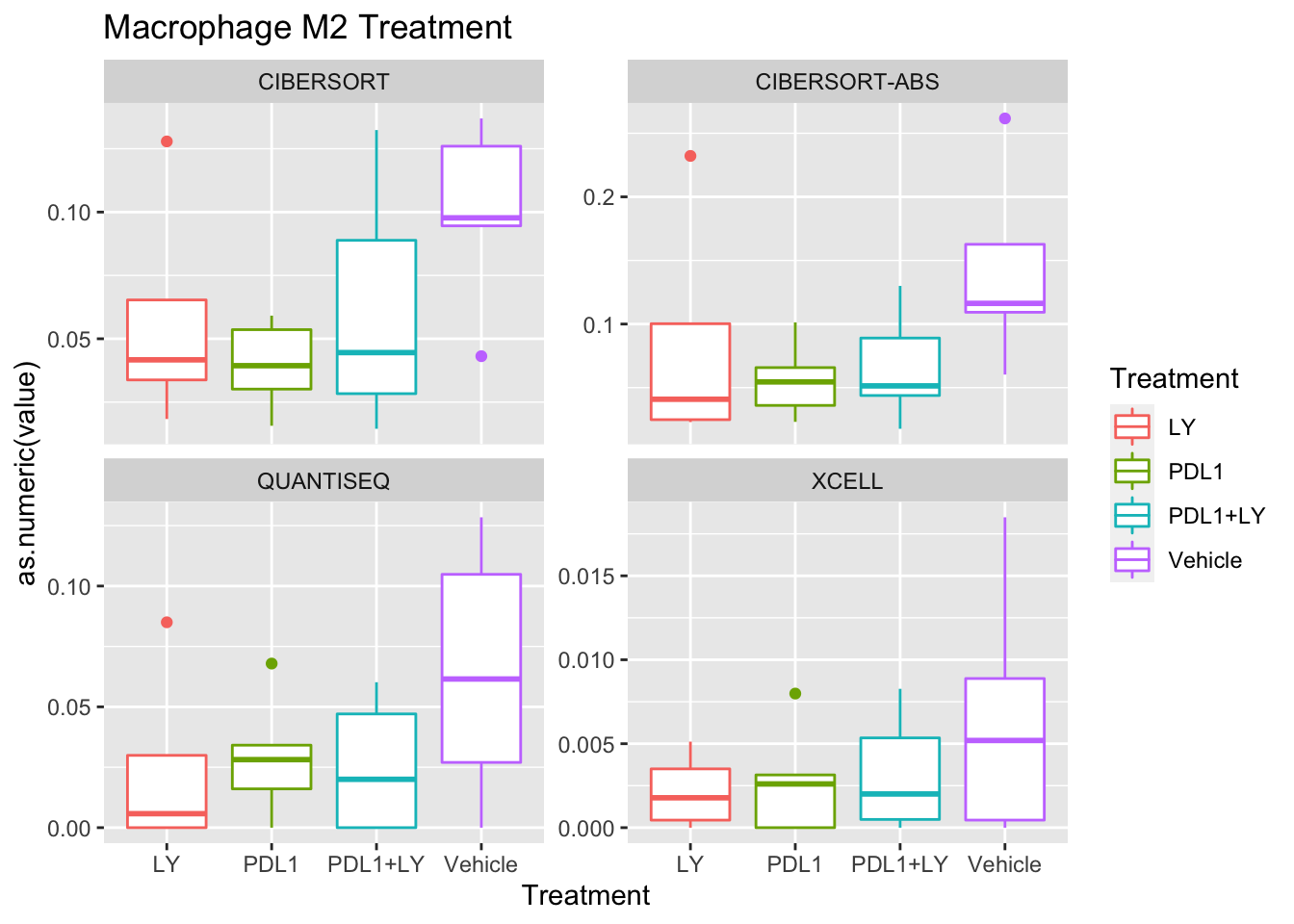
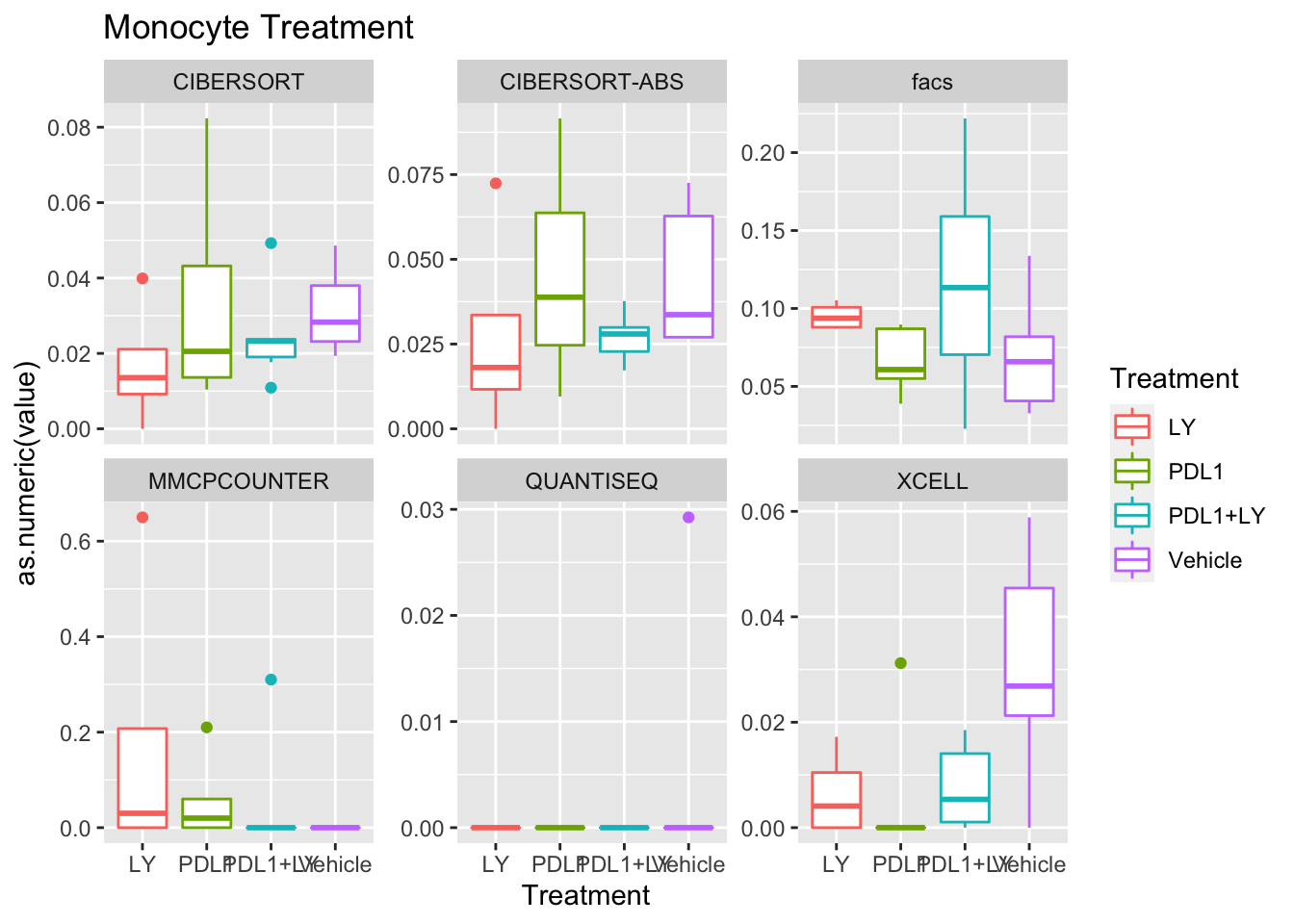
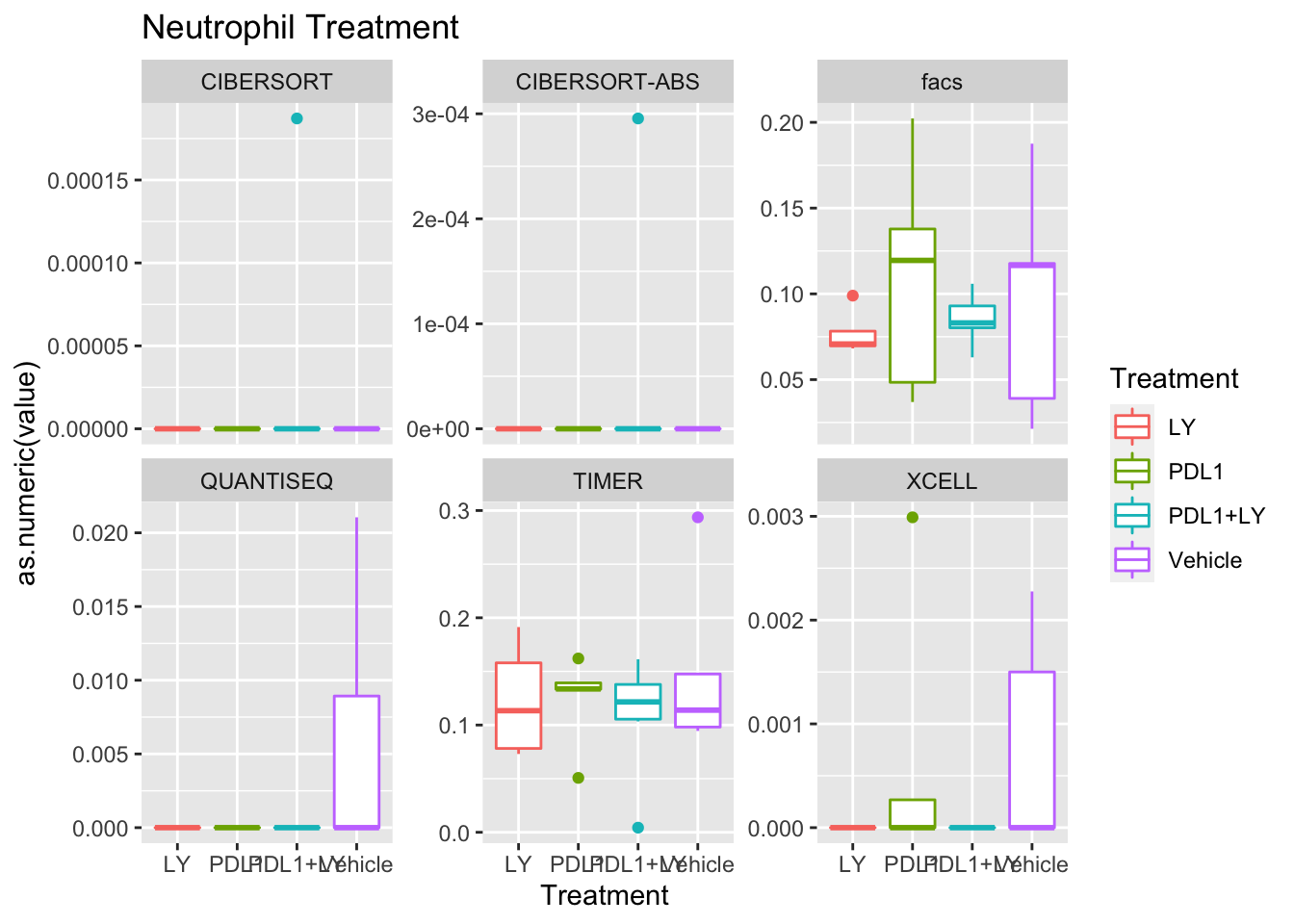
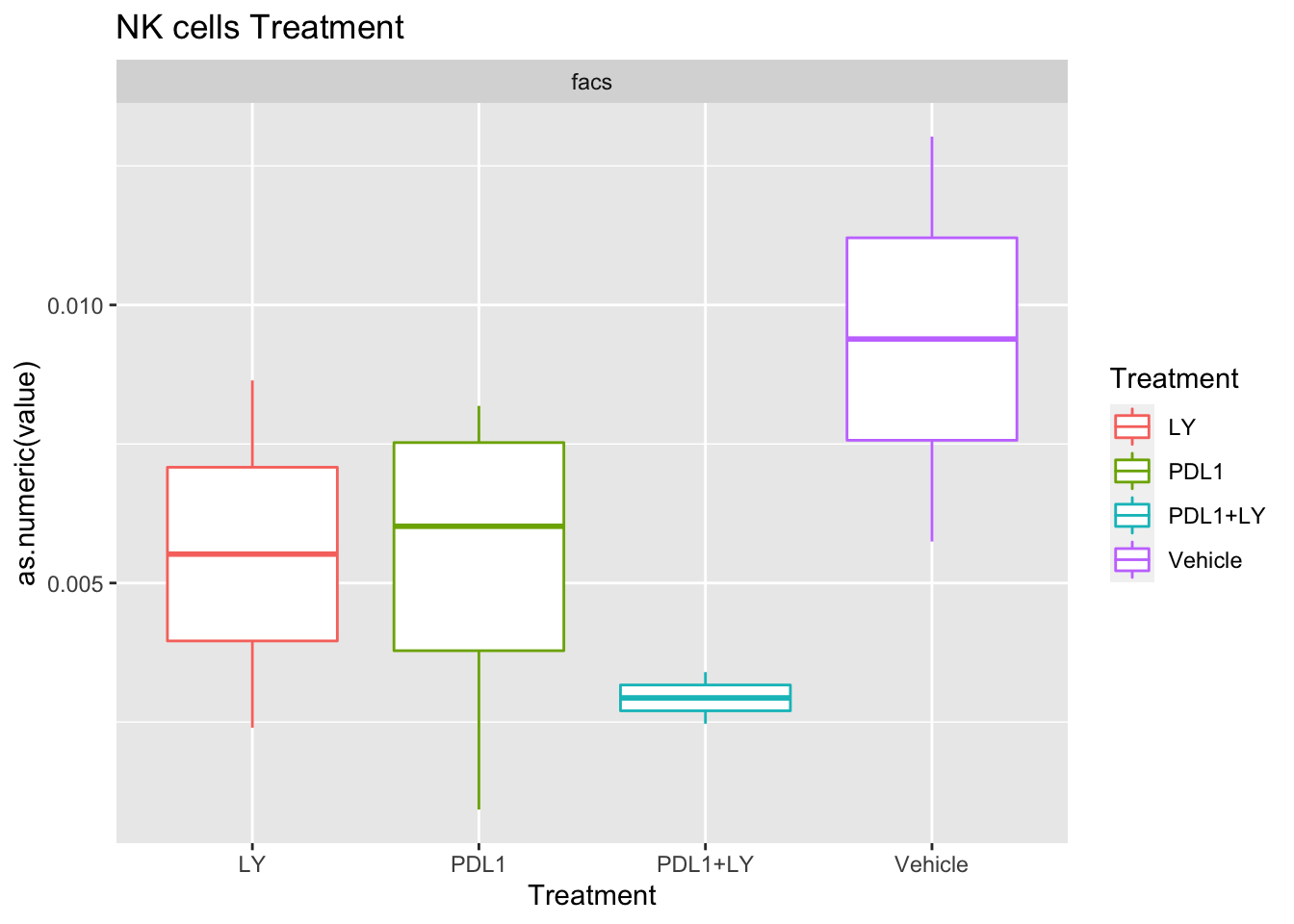
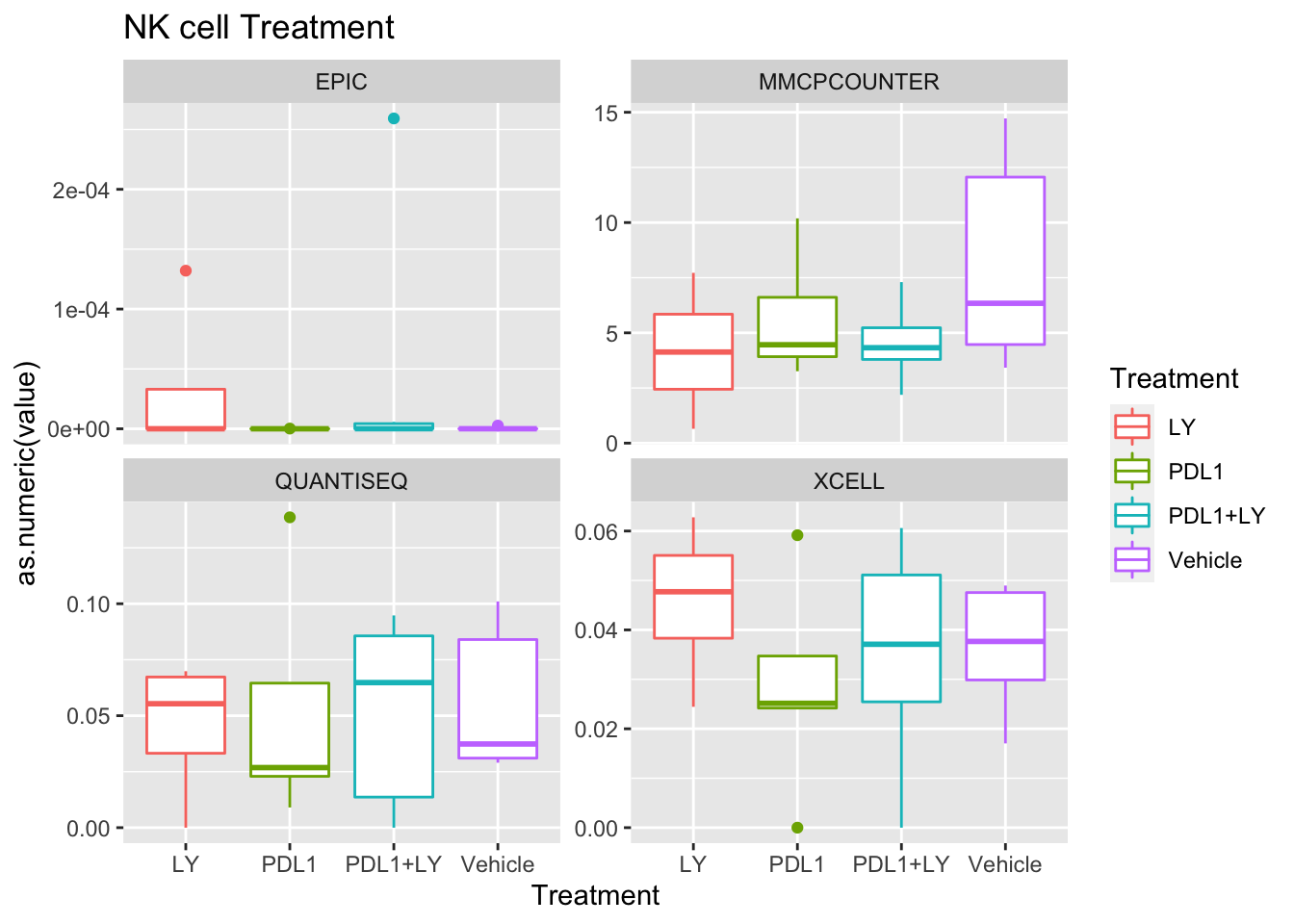
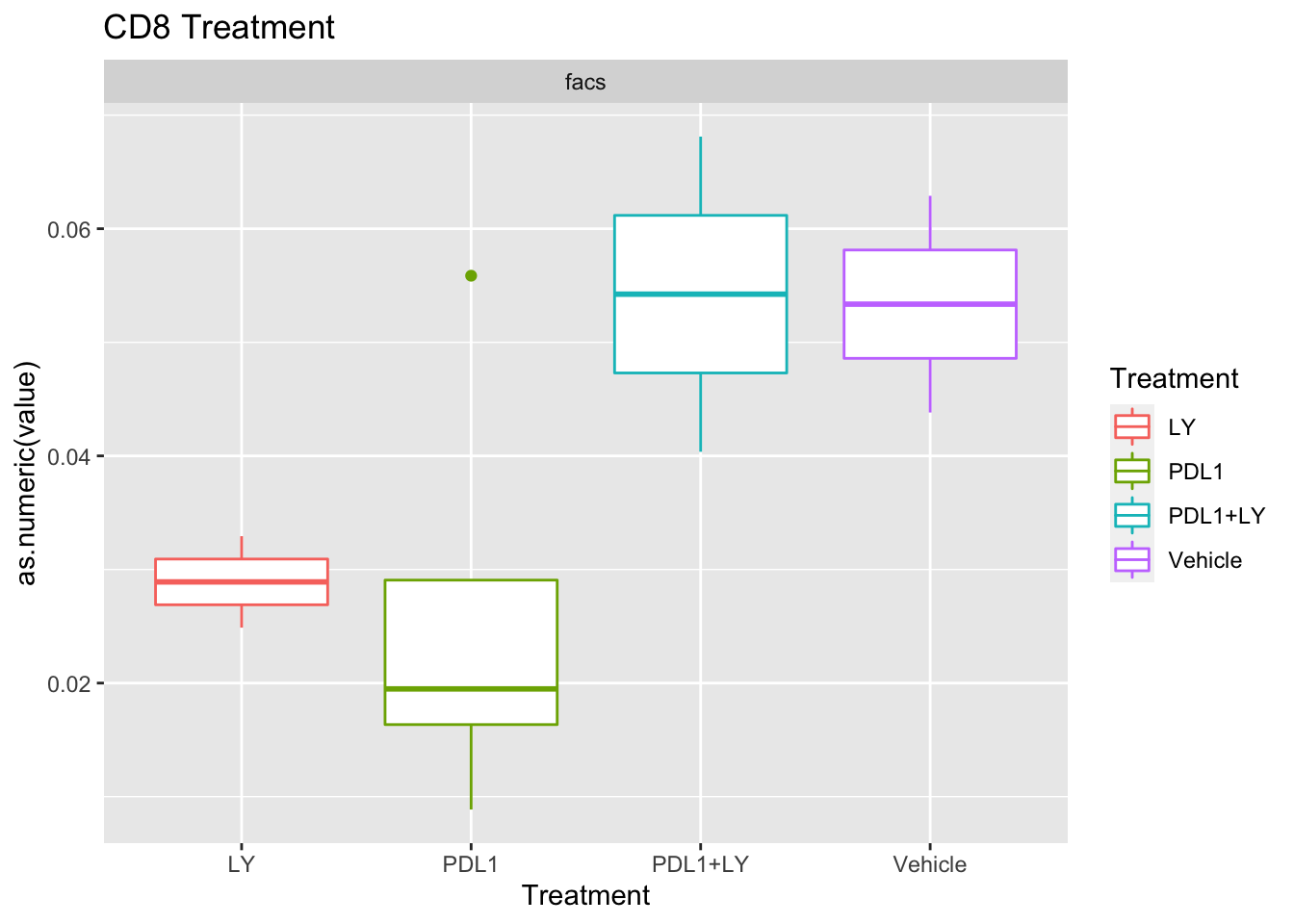
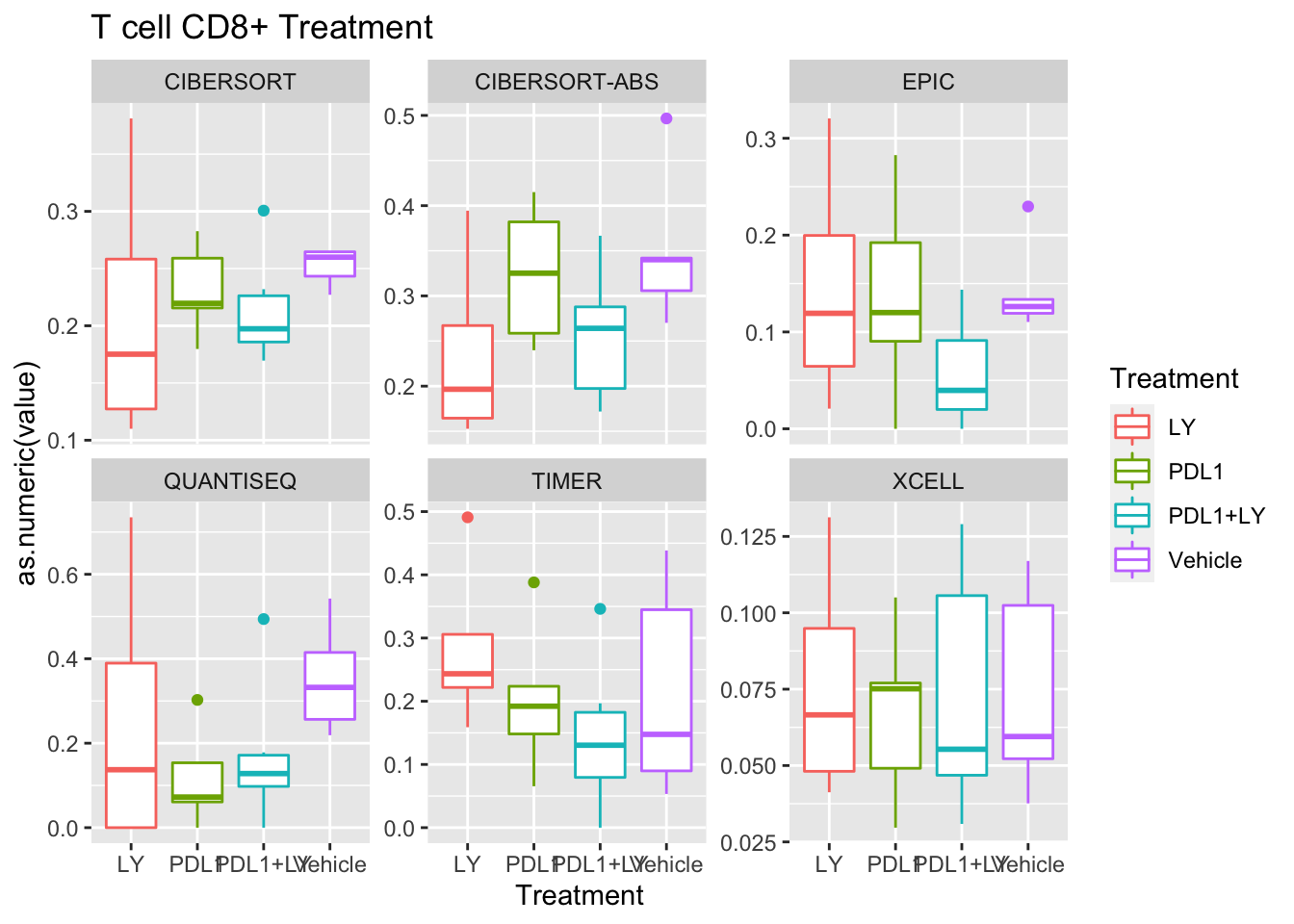
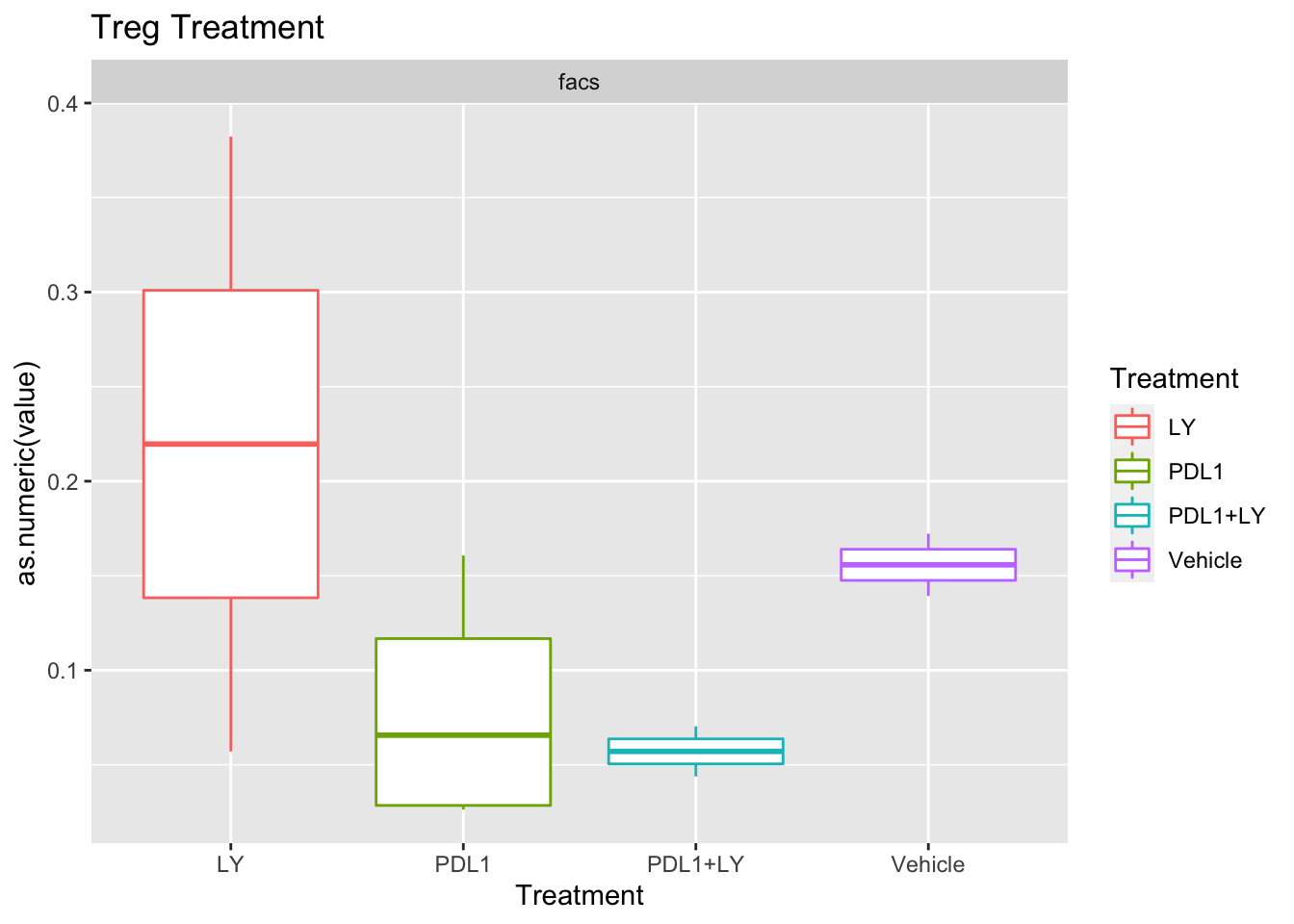
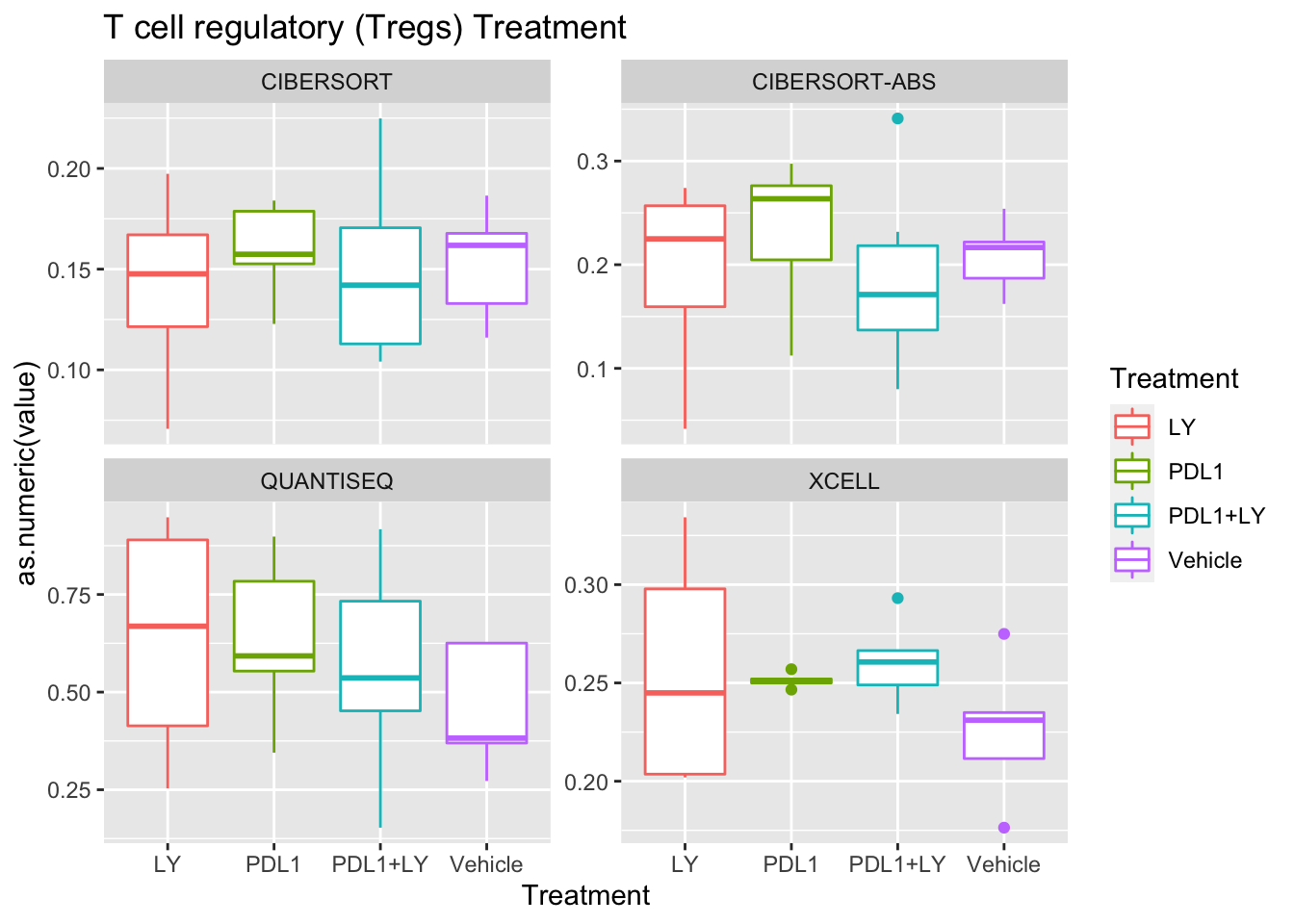
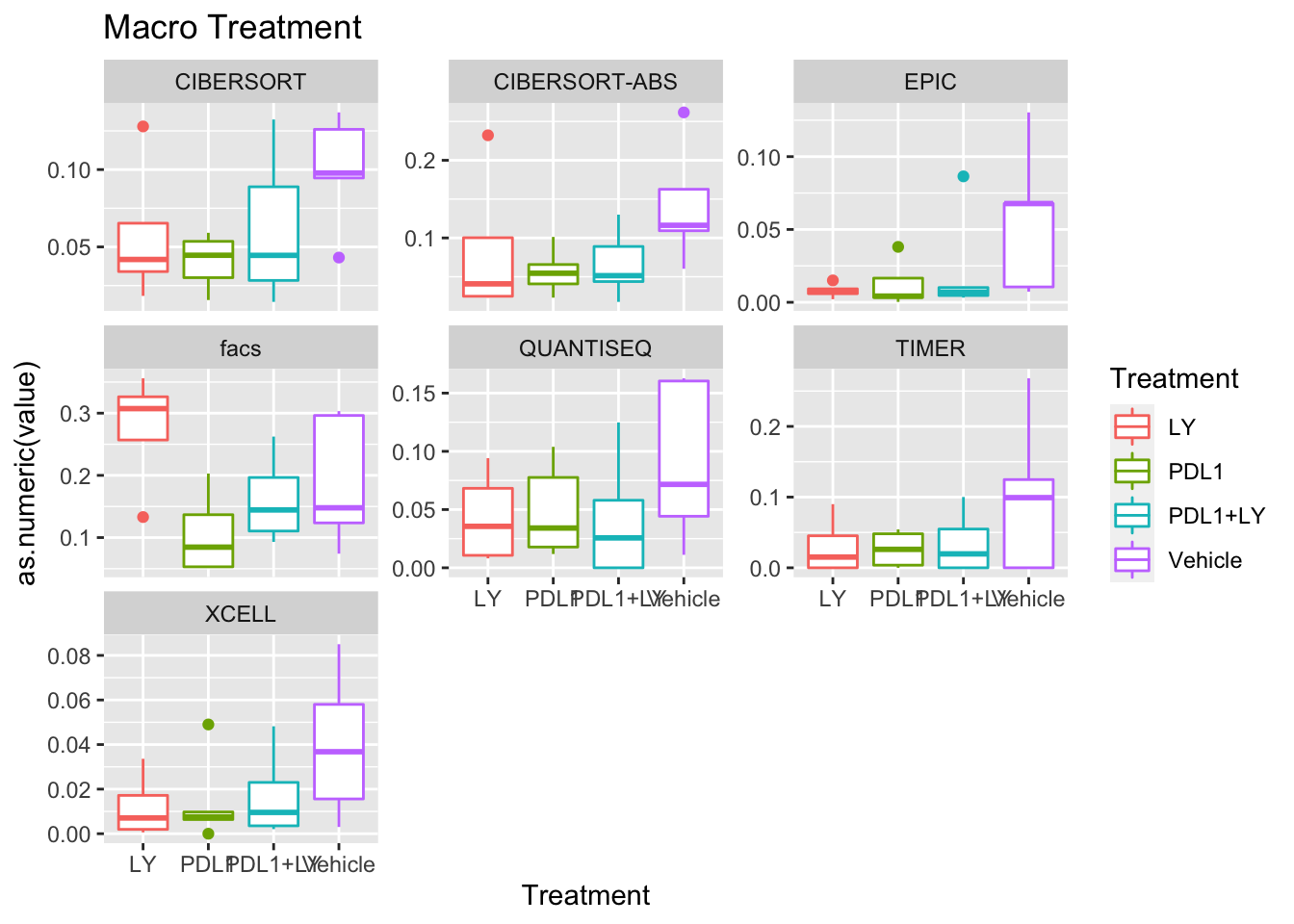
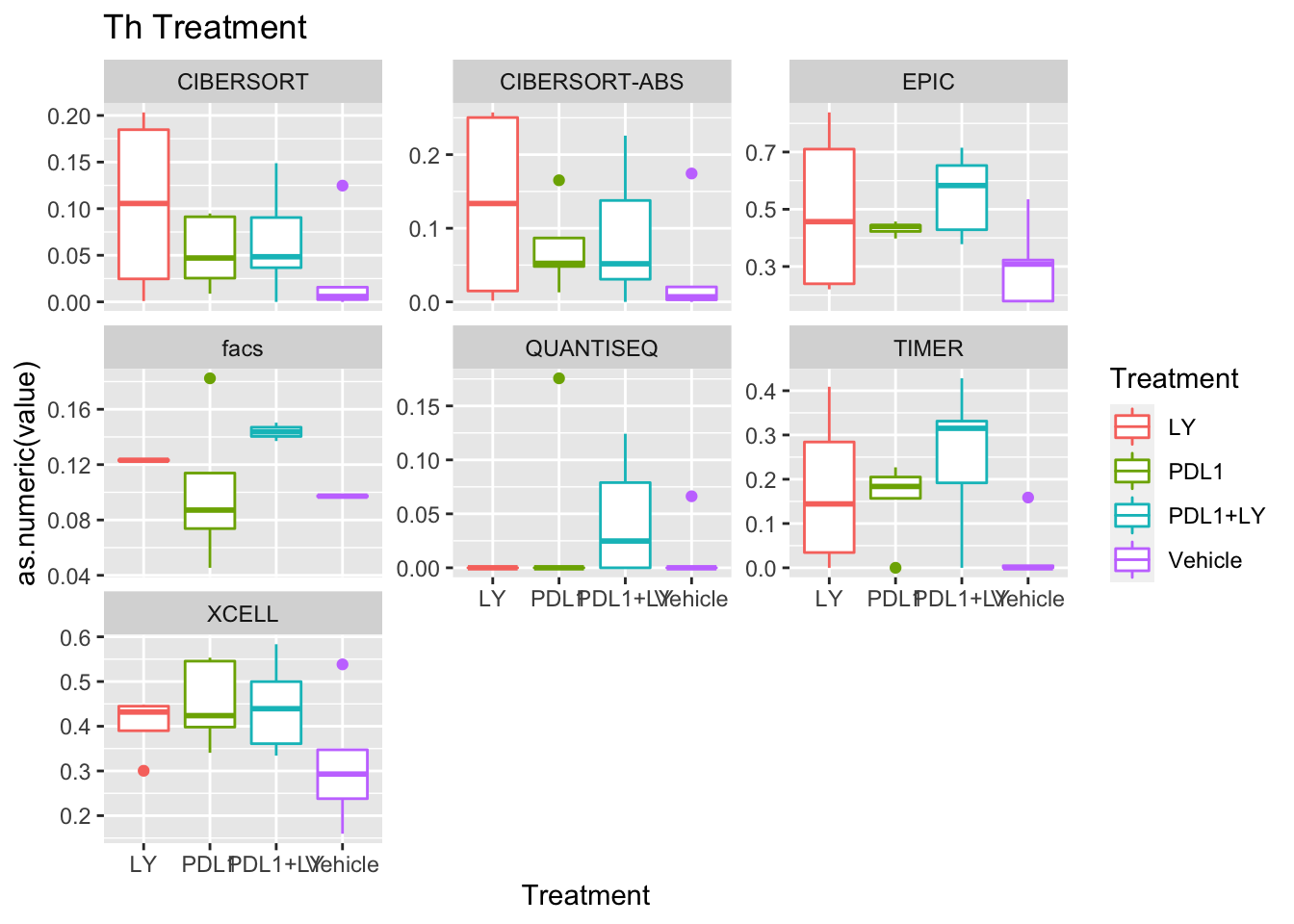
Using wilcox tests for significance, we can make the above comparisons and see if there is an association with outcome:
- There are differences in B-cell content between LY vs V comaprisons using xcell and cibersort
- Macrophages are different in PDL1+LY
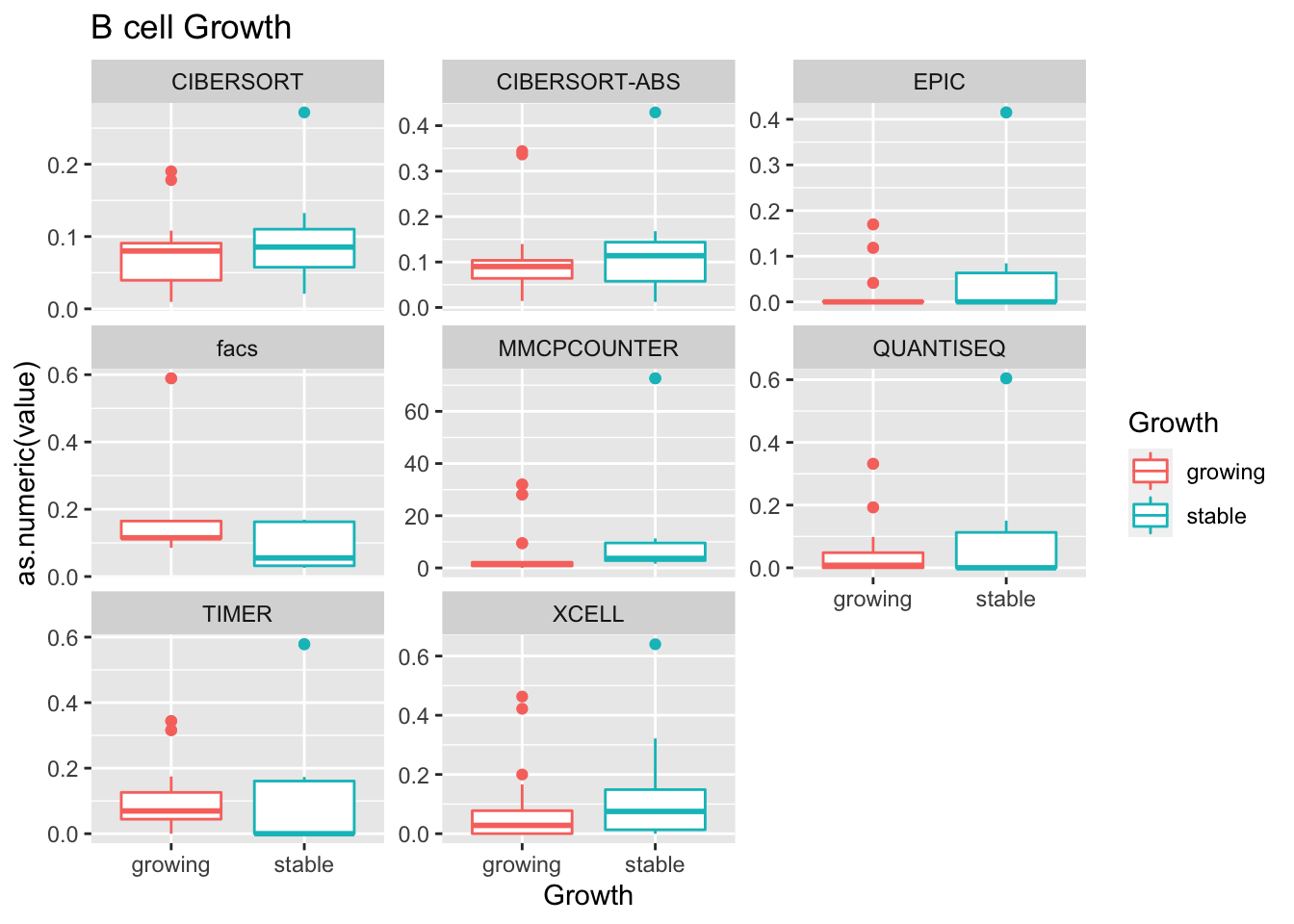
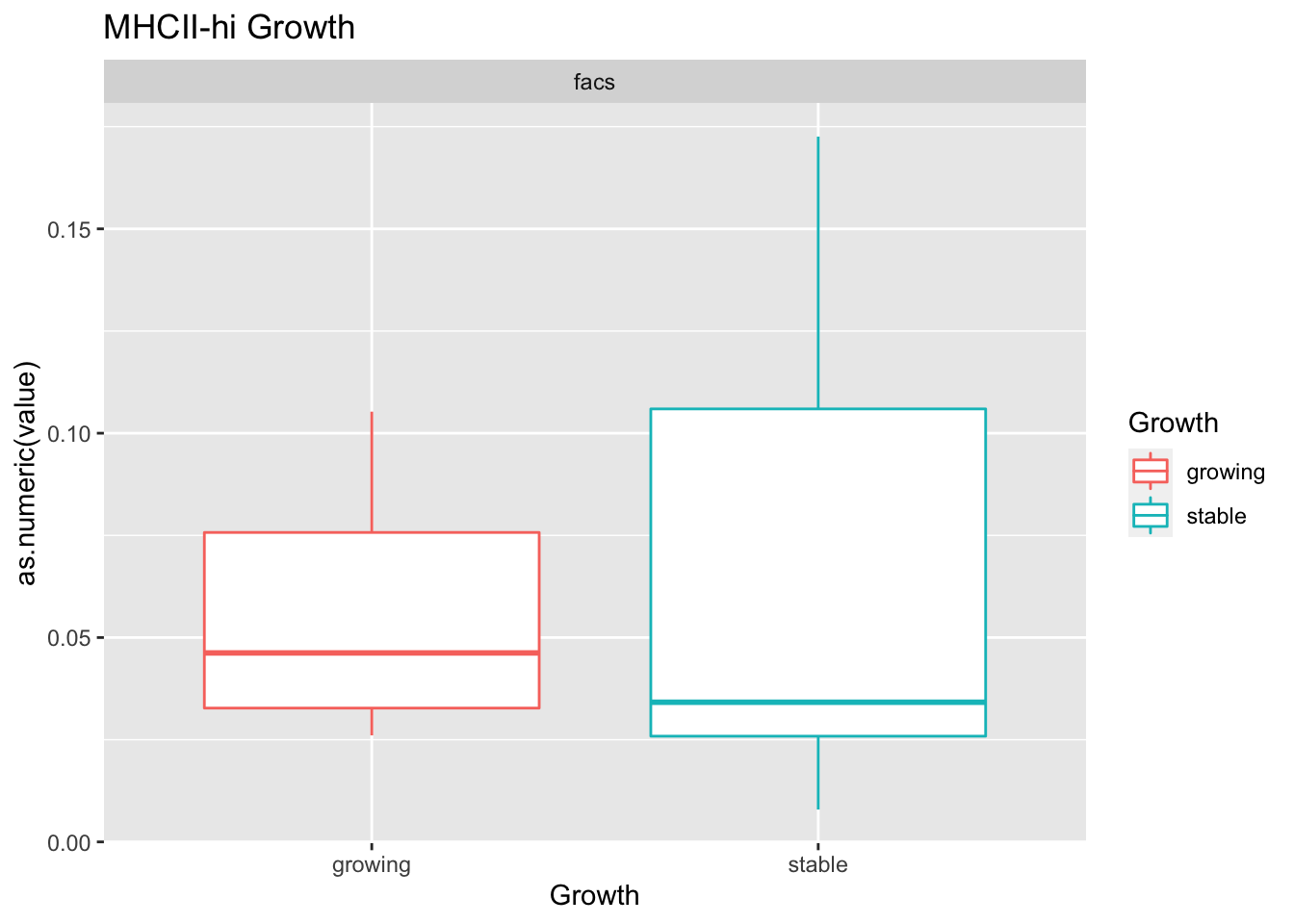
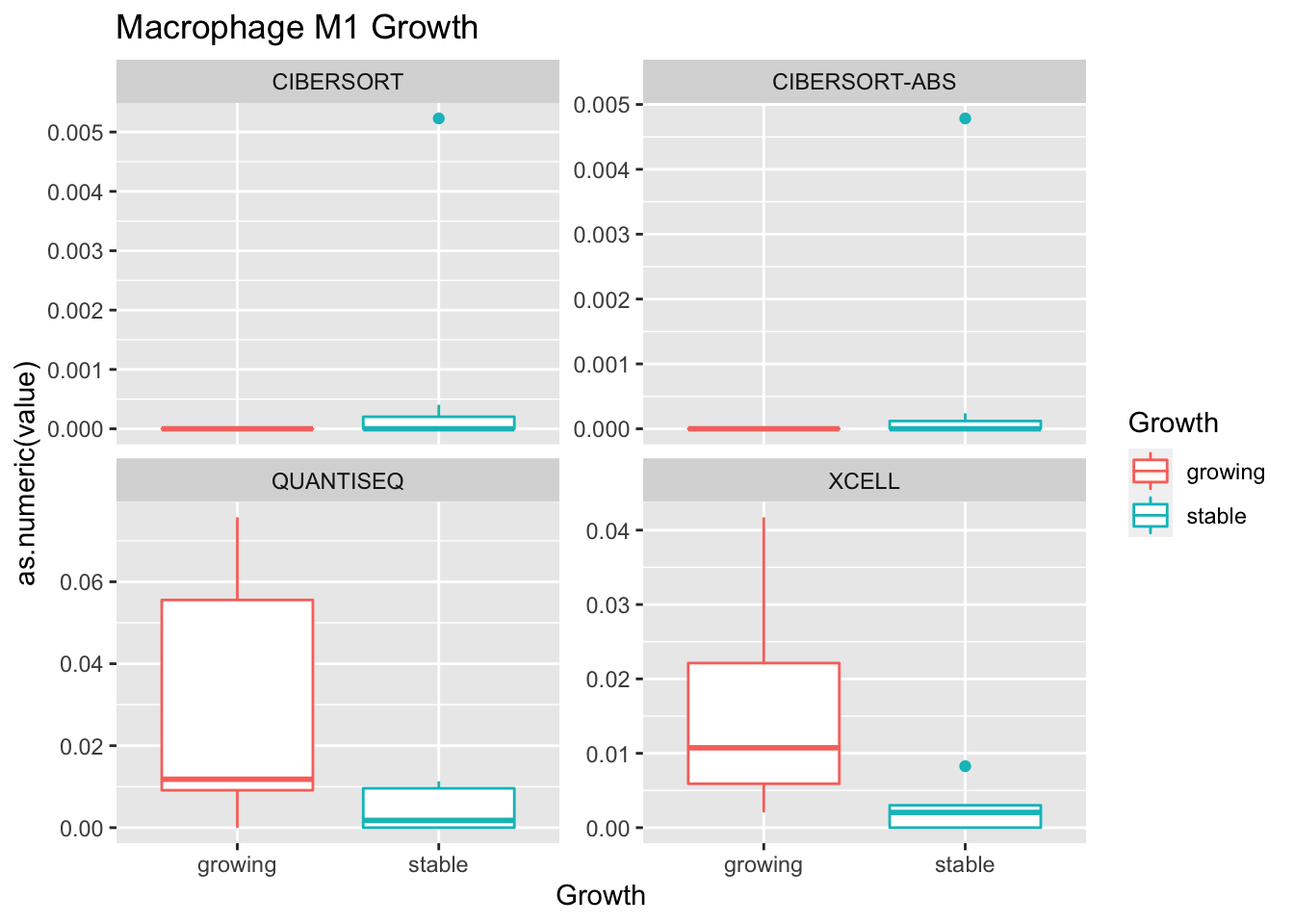
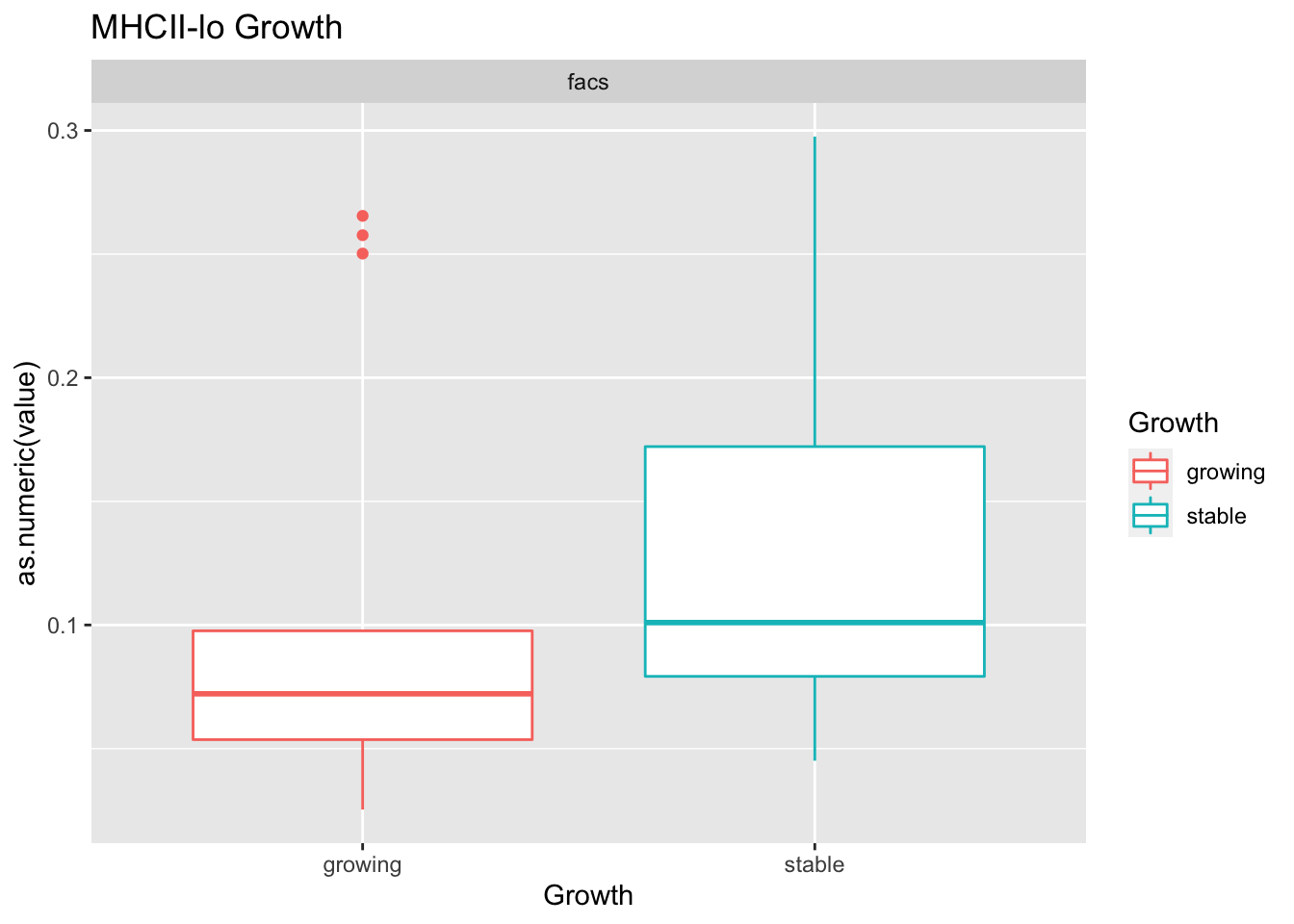
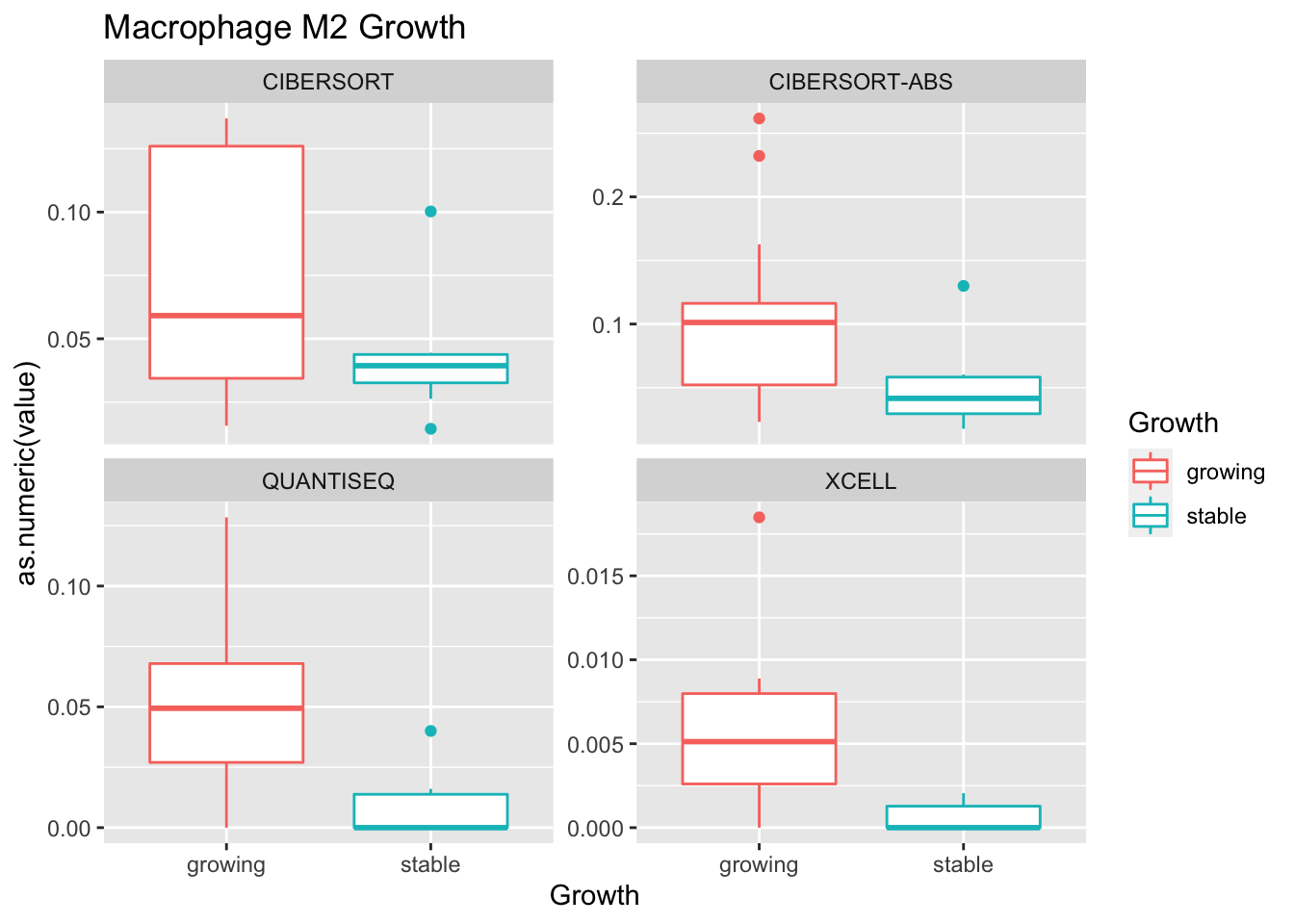
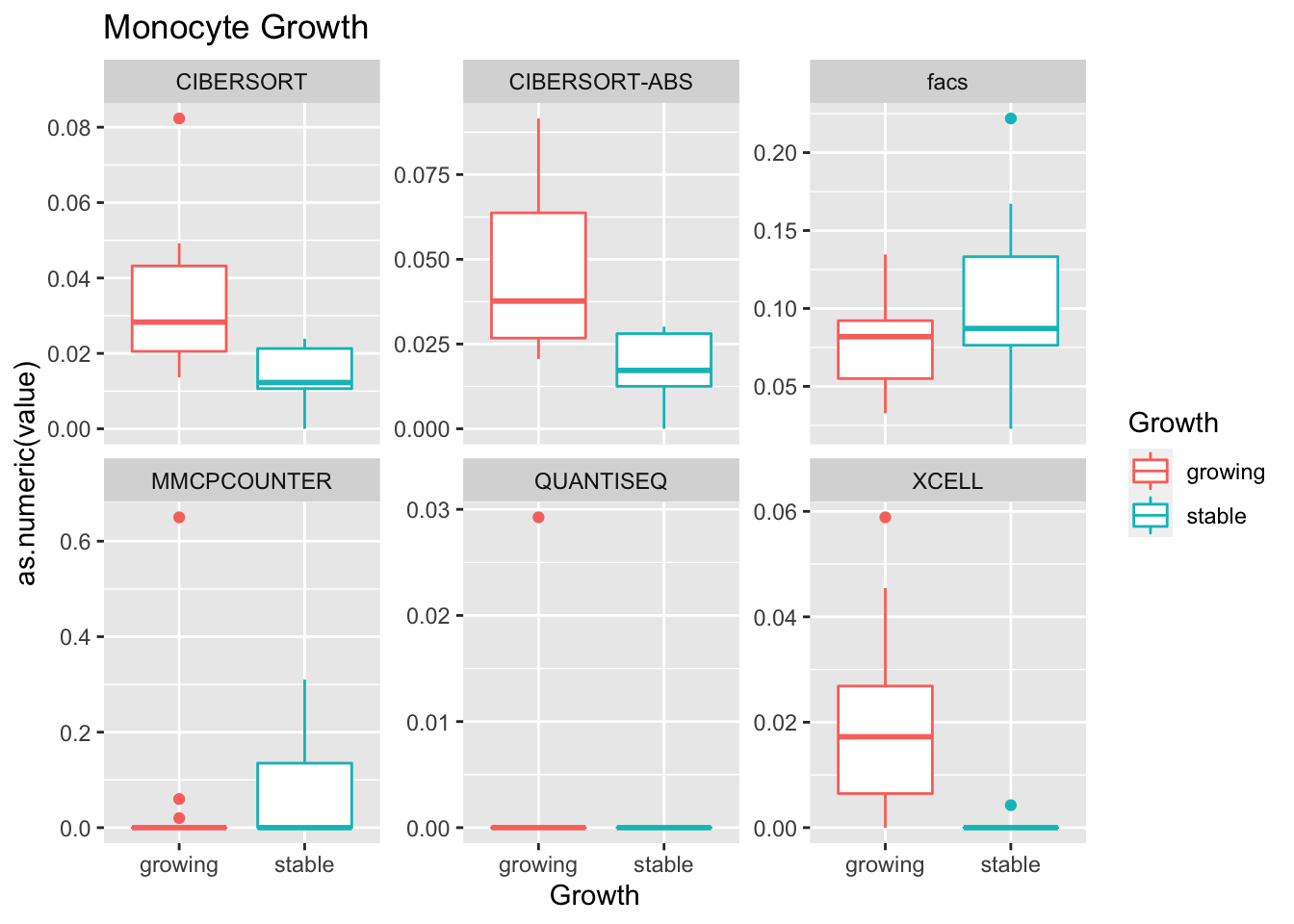
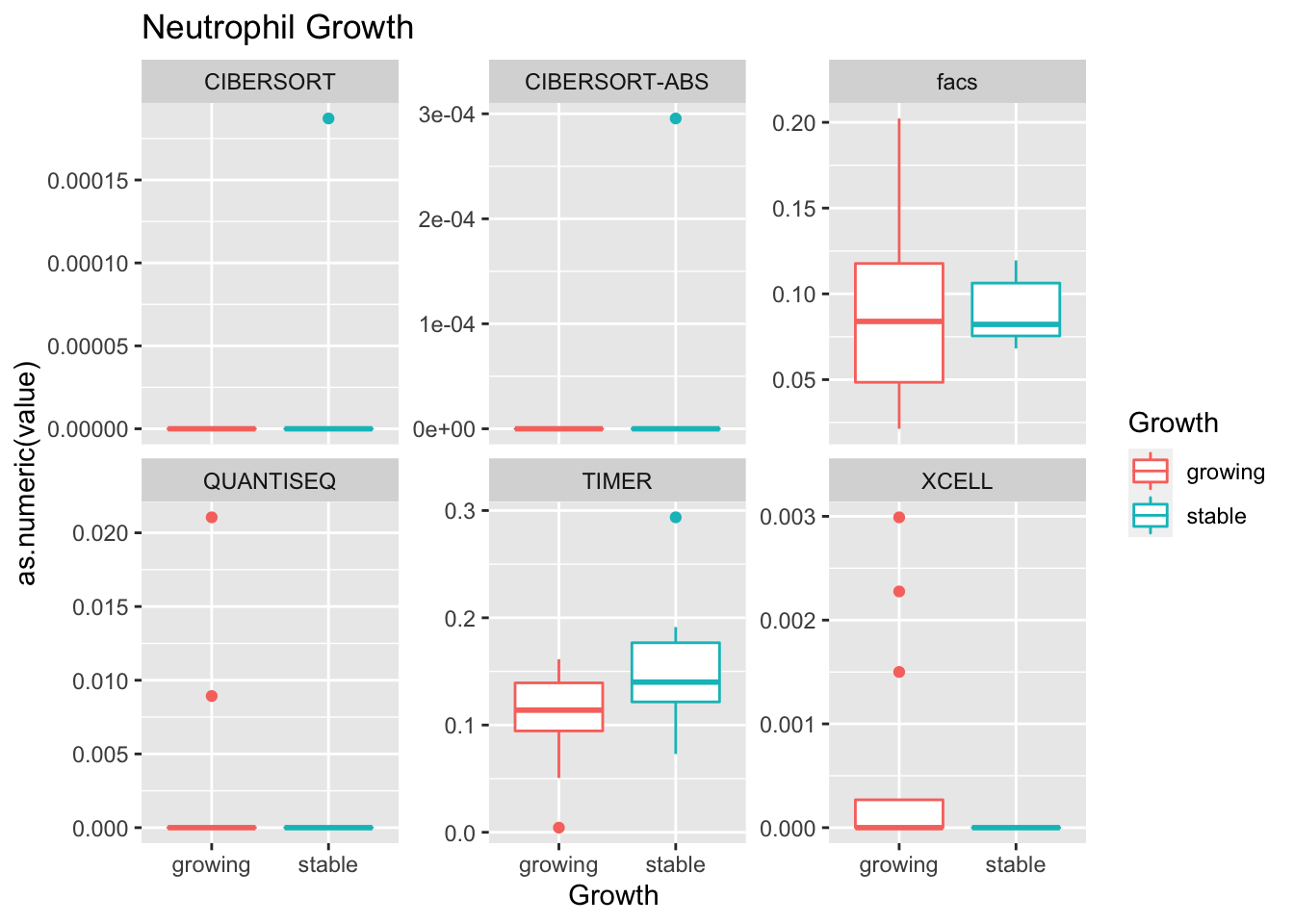
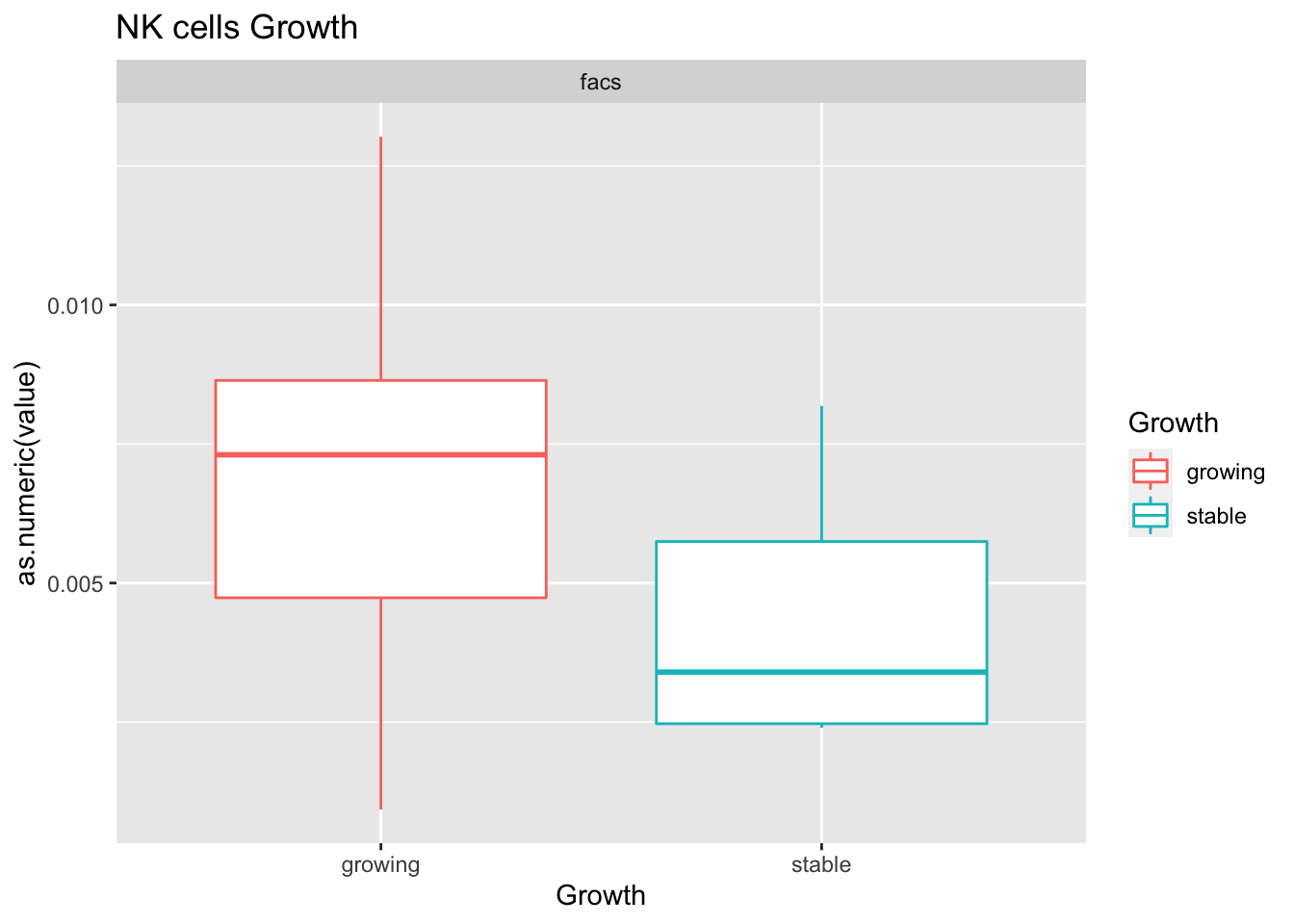

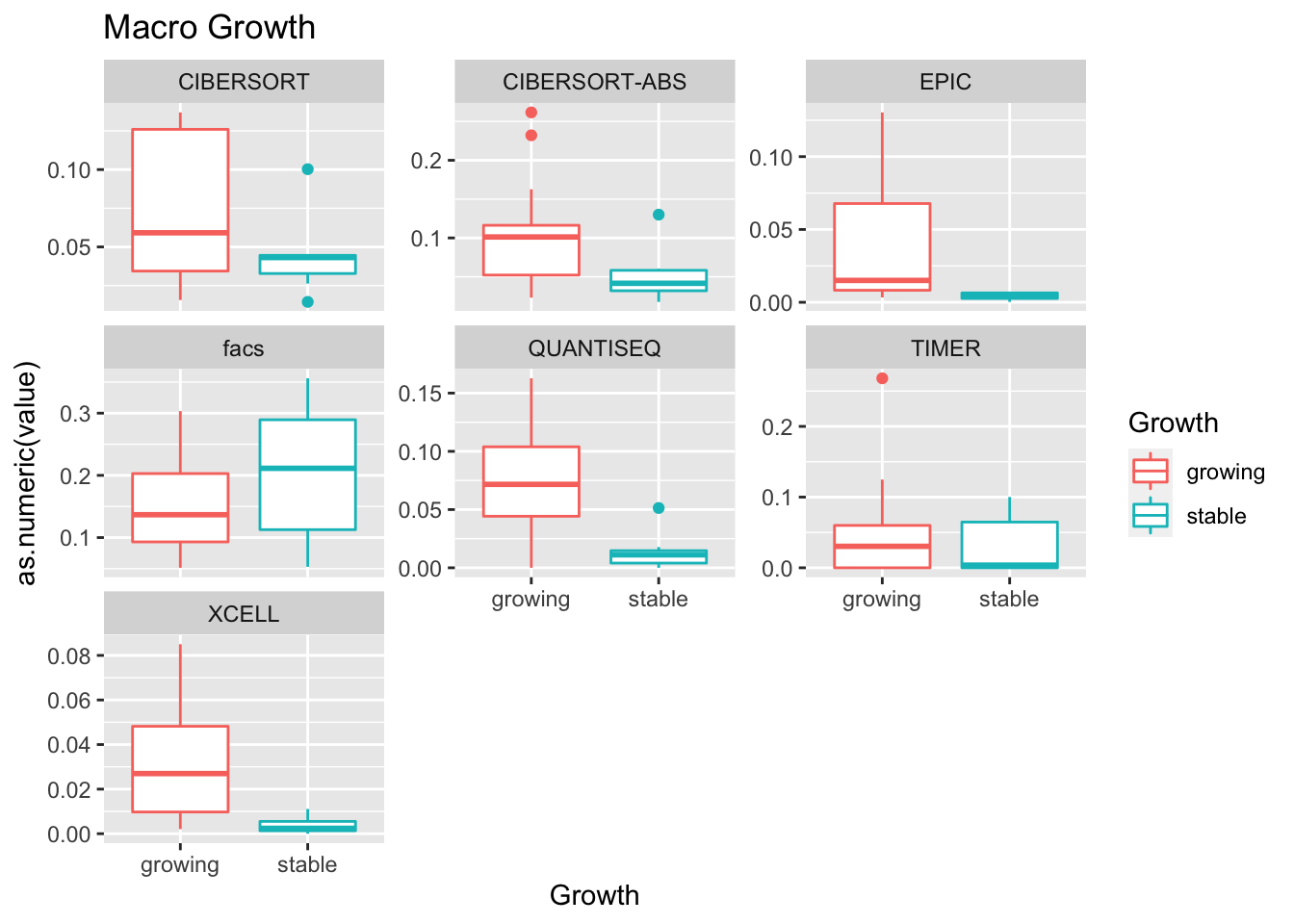
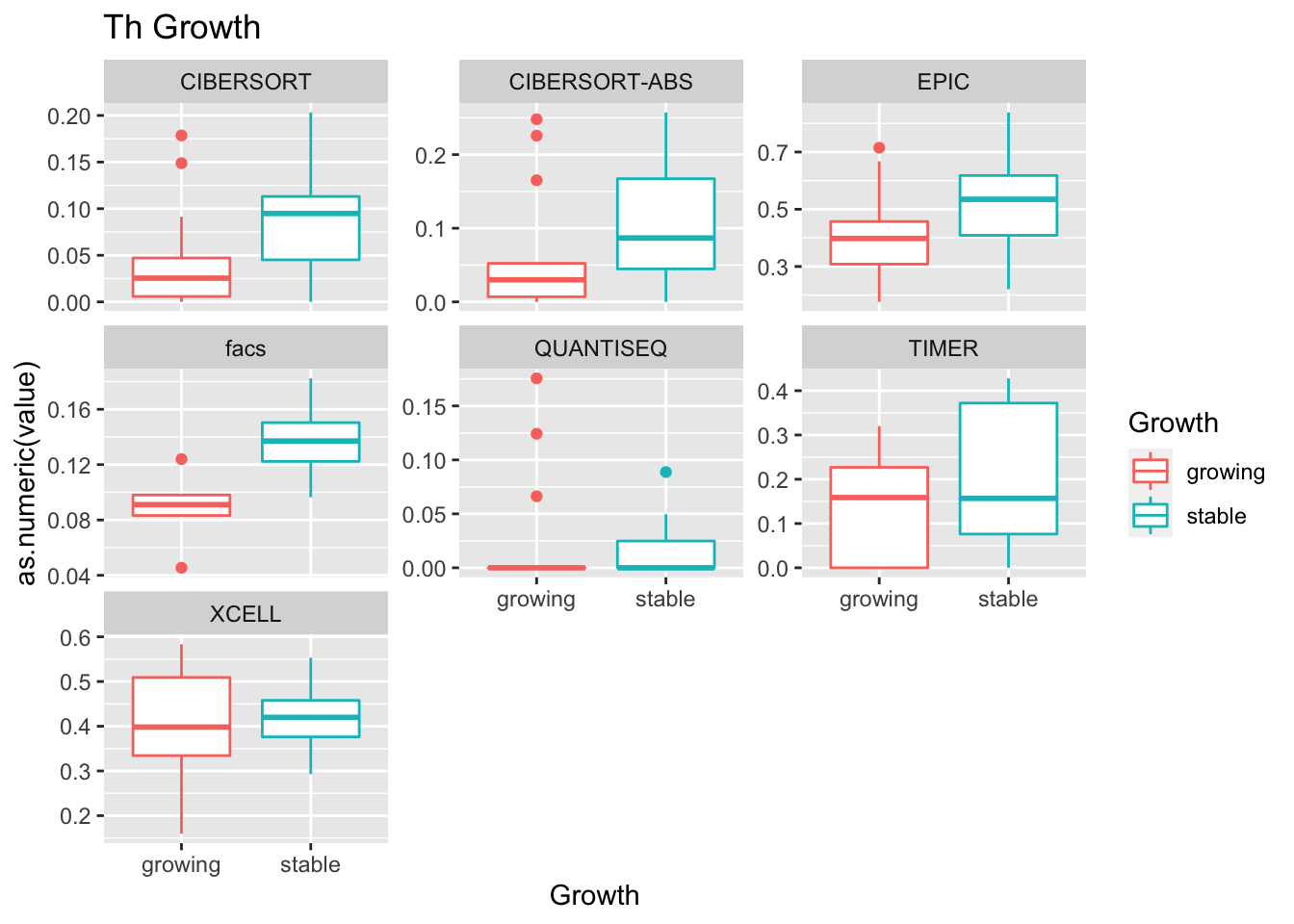
19.6 Summary of the outcome
CompTest2=do.call(rbind, CompTest)
#write.csv(CompTest2, file=sprintf("outputs/p_values_differences_treatment_growth_infiltration_%s.csv", Sys.Date()))
CompTest2=data.frame(CompTest2)
DT::datatable(CompTest2, rownames=F, class='cell-border stripe',
extensions="Buttons", options=list(dom="Bfrtip", buttons=c('csv', 'excel')))